
3. Az adatbázis szakterületi hatóköre
Szélesebb értelemben az adatbázis tárgya határozza meg a benne feltárt anyagot. A cél, hatókör magába foglal olyan szempontokat, mint a szakterület, méret, összetétel, frissesség, a forrásdokumentumok és -tárgyak (folyóiratok, cégek, zenei hangfelvételek) feltártságának mértéke, nyelv és földrajzi eredet szerinti feltártság. Szűkebb értelemben a hatókör az adatbázis tárgyi lefedettségét határozza meg. Egyes feltételek, mint a szakterület, a méret, a források köre kölcsönös kapcsolatban vannak egymással és ebben az összefüggésben kell szemlélni őket.
Hogy milyen jó egy adatbázis hatóköre, szubjektív kérdés. Ki kell elégítenie egyéni használó, illetve egy könyvtár vagy intézmény használóinak érdeklődését. A weben született adatbázisok egyik legvonzóbb jellegzetessége, hogy mély és széles lefedettséget biztosíthatnak egy nagyon speciális témában, amely viszonylag kevés ember elsődleges érdeklődési területe. A Climbing Database (hegymászók adatbázisa) http://www.climbingboulder.com és a kiváló Biographies of Women Mathematicians (matematikusnők életrajzai), amely körülbelül 100 tudósról tartalmaz életrajzi esszét (http://www.agnesscott.edu/lriddle/women/women.htm), jó példák lehetnek erre.
Valamivel szélesebb a 4000 Years of Women in Science (A nők 4000 éve a tudományban) életrajzi adatbázis (http://crux.astr.ua.edu/4000WS/4000WS.html) szakterülete. Valamivel több tételt tartalmaz (körülbelül 140-et 1999 végén), de valamivel szűkebb időszakot ölel fel, mert elsősorban a 20. század előtti tudósnőket vesz fel. Az archINFORM adatbázis (3.1. ábra) körülbelül 8000 20. századi építészeti tervről tartalmaz információkat, s azt illusztrálja, hogy valóban a kicsi is szép lehet (http://www.archINFORM.net). Az ilyen adatbázis nem lenne megvalósítható egy nagy kereskedelmi online vagy CD-ROM kiadó számára korlátozott tárgya és kis célcsoportja miatt. Még akkor is, ha egy adatbázis kicsi, megvalósítható a weben, s méltányolni kell, amikor a tárgyra vonatkozó nyilatkozat világos és egyértelmű, vagyis megfelelő módon tájékoztatja a használót.
Például az AIAA Meeting Papers kereshető bibliográfiai adatbázisa (3.2. ábra) világossá tette tárgyát honlapján (http://www2.aiaa.org/Research). (A megadott címről ma már a http://www.aiaa.org/content.cfm?pageid=413 címre irányítják át a használót, ahol az AIAA elektronikus könyvtára található, a http://www.aiaa.org/content.cfm?pageid=2 cím alatt tájékoztató is olvasható az adatbázis használatáról.) Így tett a Pennsylvania Flora Project Database (http://www.upenn.edu/paflora/dbsearch.html) is. (Erről a címről ma már a http://www.paflora.org/search.html címre irányítják át a használót, ahol már nincs meg az adatbázis leírása.)
Üdvözöljük az archINFORMnál
Ez az építészeti adatbázis, amely eredetileg építészhallgatók érdekes építészeti terveinek rekordjaiból alakult ki, időközben a nemzetközi építészet legnagyobb online adatbázisává vált.
Az adatbázis több mint 7500 megépített és meg nem valósított tervet tartalmaz különböző építészektől és tervezőktől. Az adatbázis fő témája a 20. század építészete.
Az építész, a város vagy kulcsszó szerint lehet terveket keresni az indexek segítségével vagy egy keresőűrlapot használva.
A legtöbb tétel esetében megkapják a nevet, címet, kulcsszavakat és a további irodalomra vonatkozó irodalmat. Egyes tételek tartalmaznak képeket, kommentárokat, más weboldalakhoz vezető vagy belső ugrópontokat. Azokat a terveket, amelyekben kép is szerepel, a "mediaball" jelzi az indexekben.
3.1. ábra: Az archINFORM adatbázis tárgyával kapcsolatos nyilatkozata
Az AIAA Meetings Papers Searchable Database 1992-től máig
Az AIAA Meetings Papers Searchable Database-t (konferencia-előadások kereshető adatbázisa) negyedévenként aktualizáljuk, az AIAA 1992-től máig rendezett konferenciáin tartott előadásokhoz kapcsolódóan azok szerzőire, címére, az előadás sorszámára és a konferencia dátumára és helyére vonatkozó információkat tartalmaz

3.2. ábra: Az AIAA magyarázata adatbázisának tárgyáról
Egy adatbázis neve vagy rövidítése gyakran utal a benne feltárt anyag tárgyára. Például a Library Literature, Library and Information Science Abstracts és a Mental Health Abstracts egyértelműen meghatározza az adatbázis szakterületét. A PsycINFO és a PsycLIT is utal tárgyára. Néha az adatbázis neve önmagában nem lehet elég informatív. Az Information Science Abstracts számos könyvtártudományi és információtechnológiai folyóiratot is feltárt, ahogy azt összes verziójának implementációjában szereplő tárgyi megjegyzések is világossá teszik (3.3. ábra).
Csak tesztkeresések tudják igazán feltárni, mi van a névben vagy a név mögött. A feltártságra vonatkozó állítások kérésre opcionálisan megjelennek (mint például amikor rákattintunk az i szimbólumra az Ovid adatbázisaiban, vagy megadjuk a ?file 202 parancsot a DIALOG-ban) szintén tájékoztatással szolgálhat az adatbázis tárgyköréről. Figyelni kell arra, hogy fájl előállítói vagy az adatbázis kiadói honlapján szereplő reklámszövegek mellett, ezeket az állításokat is gyakran némi kétkedéssel fogadjuk (gyakran erős kételkedéssel).
Az 5. fejezet azt az esetet illusztrálja, amikor az Information Science Abstracts adatbázis szerkesztőjének állítása szűkíti az ISA tárgykörét, amely a szerkesztő szerint az információtudomány, szemben más adatbázisokkal, mint a Library Literature és a Library and Information Science Abstracts, amelyek a könyvtár- és információtudományt dolgozzák fel. Ez megzavarhatja a használókat, akik a DIALOG adatbázis-leírásának (bluesheetjének) a fájlt leíró részében azt olvassák, hogy "az Information Science Abstracts bibliográfiai adatokat és referátumokat szolgáltat az információtudomány és a könyvtártudomány területéről" (http://library.dialog.com/bluesheets/html/bl0202.html). (Az ISA adatbázisa jelenleg nem érhető el a DIALOG-nál, így természetesen ez a leírás sem.) Másrészt vannak olyan adatbázisok, amelyek reklámszövegei teljes mértékben megfelelnek a valóságnak. Ilyen az H. W. Wilson adatbáziscsalád egésze (3.4 ábra).
Fájlleírás
Az Information Science Abstracts bibliográfiai adatokat és referátumokat szolgáltat az információtudomány és a könyvtártudomány területén. Anyagában nemzetközi, az adatbázis több mint 300 folyóiratból indexel és referál cikkeket, valamint könyveket, kutatási jelentéseket, kongresszusi kiadványokat és szabadalmi leírásokat. Minden rekord tartalmaz bibliográfiai adatokat és referátumokat, továbbá deszkriptorokat

3.3. ábra: Az Information Science Abstracts adatbázis tárgyának meghatározása
A Wilson Library Literature Database bibliográfia adatbázis, amely 354, az Amerikai Egyesült Államokban vagy máshol kiadott, alapvető könyvtár- és információtudományi periodikumot indexel. Könyveket, könyvfejezeteket, kongresszusi kiadványokat, könyvtári szakdolgozatokat és brosúrákat is indexel.

3.4. ábra: Egy Wilson adatbázis tárgyának meghatározása
Az Elsevier cég által kiadott Scirus címjegyzék esete világosan illusztrálja, hogy sem a nevet, sem a kiadó állításait az adatbázis tárgyáról nem lehet szó szerint venni. Az Elsevier minden képernyőn szembetűnő módon megjelenít egy logót, közhírré téve, hogy "Scirus, színtiszta tudományos információ". E könyv szerzője, aki a Scirusban az összehasonlító vallástudomány referenszforrásaira vonatkozó tudományos információt keresett, olyan weblapokra mutató linkeket kapott, amelyek a címlapjukon a legvulgárisabb szavakat tartalmazták. Egy másik, a négybetűs szavakra végzett keresés 38000 találatot hozott. Néhány lapnak a meglátogatása igazolta, hogy ez a címjegyzék nem kizárólag tudományos információt tartalmaz. (http://www2.hawaii.edu/~jacso/extra/infotoday/scirus/scirus.html).
Az átfogó szó a fájlok előállítóinak a fájl tárgyára vonatkozó állításaiban nagyon gyakran előjön, de ennek a szónak a jelentését nyilvánvalóan különböző módon interpretálják. A Bowker-Saur World Databases, amely körülbelül 10000 rekordot tartalmaz, átfogónak (mindenre kiterjedőnek) mondja magát kiadói reklámjában. A Gale cég Directory of Databases szintén átfogónak mondja magát, és 15000 adatbázisra vonatkozó rekordjával az állítás sokkal inkább igazoltnak tűnik. Ha ehhez a tényhez azt is hozzátesszük, hogy a World Databasesnek az adatbázisok minden egyes implementációjáról külön rekordja van, míg a Gale egyetlen rekordot készít médiatípusonként (azaz egy rekordot a MEDLINE online verzióira és egy másikat a CD-ROM-verziókra), a World Databases átfogó jellegére vonatkozó állításai még irreálisabbnak látszik. Az ebben a bekezdésben említett adatbázisokra vonatkozó tesztkeresések igazolják azt a benyomást, hogy a Bowker-Saur adatbázis messze van a teljességtől.
Nem voltak benne rekordok olyan adatbázisokról, mint a Library Literature vagy a Library and Information Science Abstracts, annak ellenére, hogy az utóbbi nem csak brit adatbázis, hanem gondozója - jól gondolta, kedves olvasó - a Bowker-Saur. A library és a literature szavakra vonatkozó együttes keresés egyetlen rekordot talált, az Information Science Abstractset, mert ez azt állítja magáról, hogy feldolgozza a könyvtári szakirodalmat (3.5. ábra). Az azokra a tételekre vonatkozó keresés, amelyekben a microcomputer és az abstracts szavak egymás mellett állnak, csak egy rekordot talál, a Computer Abstractset, s nincs rekord a Microcomputer Abstractsre vonatkozóan. (Erre a keresésre még azelőtt került sor, mielőtt az adatbázis Internet and Personal Computing Abstractsre változtatta volna a címét.) Nem meglepő, hogy a World Databases címjegyzéknek nincs tétele magára a World Databasesre vonatkozóan sem. Soha nem is aktualizálták.

3.5a. ábra: Nincs rekord a Library Literature adatbázisra.
A Gale Database of Publications and Broadcast Media azt állítja, hogy "átfogó adatbázis, amely részletes információt tartalmaz 61000 újságról, magazinról, folyóiratról, periodikumról, címjegyzékről, hírlevélről és rádió-, televízió- és kábel állomásról és rendszerről." Levonva a rádió és televízióállomásokra és rendszerekre vonatkozó rekordokat, a maradék körülbelül 50000 periodikus kiadvány lehet. Az ilyen szűrés lehetővé teszi az összehasonlítást az Ulrich's Periodical Database-zel és az EBSCO Serials Database adatbázisával, mindkettő átfogó feltártságúnak mondja magát - és adataik körülbelül 210000 és 155000 periodikumról adnak információt.
A The Serials Directory (TSD) és az Ulrich's Periodical Database átfogó jellege mindjárt más értelmet kap annak ismeretében, hogy az ISSN Database-nek 850000 rekordja van, és a Kongresszusi Könyvtár időszaki kiadványokat tartalmazó részhalmazának pedig közel 900000 rekordja. A kisebb adatbázisok közül egyik sem említ tárgyi szűkítést, de sok ilyennek kell lennie, és némelyik közülük jogosan is alkalmaz korlátozást. Például az adatbázis tárgyának a dokumentumok nyelve és a kiadás országa szerinti korlátozása ésszerű, s megmagyarázhatja a kisebb méretet és a szűkebb tárgyat.

3.5b. ábra: Nincs rekord a Microcomputer Abstracts adatbázisra.
Lehetnek sokkal kevésbé nyilvánvaló okai is a kisebb méretnek és az adatbázis érzékelt tárgyának. Például a követő tételkatalogizálás gyakorlata (amikor a cím megváltozása után az EBSCO új rekordot hoz létre és a korábbi cím rekordja is megmarad az adatbázisban), az EBSCOt előnyösebb helyzetbe hozza az Ulrich'sszal szemben a címek teljes számát tekintve, mert az Ulrich's a legutolsó tétel katalogizálásának elvét alkalmazza. E szerint az eljárásmód szerint az újabb címre vonatkozó rekord magába foglalja a korábbi címmel kapcsolatos információkat és a korábbi cím rekordját törlik.
A megközelítés e különbsége szerint az EBSCO-nak külön rekordja van a Laserdisk Professional, CD-ROM Professional és az EMedia Professional címekre (3.6. ábra), plusz egy további rekord az E Media Professional változatra (ISSN szám és ok nélkül) és egy rekord a CD-ROM News Extra-ra, amely a CD-ROM Professional rosszul tervezett és rövidéletű melléklete volt. Az Ulrich'snak egyetlen tétele van, csak a mostani cím alatt található meg, s ez a rekord tartalmazza a két korábbi címet (3.7. ábra). Figyelembe véve a periodikumok címváltozásainak rendkívüli mértékét, ez nagyon jelentős különbséget okozhat, amikor összehasonlítjuk az adatbázisok állítólagos tárgyát a címek szavai, a kiadó, deszkriptorok, országnevek, nyelv stb. szerint tesztkeresésekkel.

3.6. ábra: Az EBSCO adatbázisában külön rekordok találhatók egy folyóirat jelenlegi és korábbi címeire

3.7. ábra: Az Ulrich'sban egyetlen rekord található egy folyóirat jelenlegi és korábbi címeire
Az adatbázis tárgya pontos mérésének másik módja tesztkeresések elvégzése. A címek indexmezőjében egy szóra (bibliometrics) vagy egy összetett kifejezésre (artificial intelligence) végzett tesztkeresés gyors és könnyű módja annak, hogy néhány témára vonatkozóan benyomást szerezzünk az adatbázis által feltárt anyagról. Néhány egyszerű keresés eredménye a használót szkeptikussá teheti vagy bizalommal töltheti el azokkal az állításokkal szemben, amelyeket az adatfájl előállítója vagy kiadója tesz a feltárt témákkal kapcsolatban, különösen azokkal, amelyeket kiemelten említenek meg a reklámanyagokban. A címekre vonatkozó keresések önmagukban nem lehetnek meggyőző erejűek (kivéve olyan extrém eseteket, amelyeket a következőkben tárgyalok). Azokkal az eredményekkel együtt kell értékelni őket, amelyek az adatbázis összetételére, kurrensségére, retrospektivitására és folyóiratbázisára vonatkozóan végeztek, valamint arra a gyakorlatra vonatkozóan, amely meghatározza a tételeknek az adatbázisba való felvételét. A kérdés kombinálható a kiadási évekkel, a keresés eredményét a legutolsó két vagy három évre korlátozva, hogy az adatbázis legfrissebb részét teszteljék. Egy ilyen kérdés így néz ki:
S supercomput?/ti AND PY=1998:2000 (a DIALOG-nál)
F supercomput* in ti AND PY=1998-2000 (a WebSPIRS-ben)
Néha a vizsgált adatbázisban végzett egyetlen teszt önmagában is kétségeket ébreszthet az adatbázis tárgyával kapcsolatban. Az előbbi keresés az ISA adatbázisban 2000 novemberében nulla találatot eredményezett. Bár az nyilvánvaló, hogy nem minden, a szuperszámítógépekkel foglalkozó cikk vagy konferencia előadás címében szerepel ez a szó, elképzelhetetlen, hogy egyetlen sincs benne egy olyan adatbázisban, amely a szuperszámítógépeket a 22 legfontosabb szakterülete közé sorolja adatbázis-leírásában, amelyet 2000-ben két alkalommal is aktualizáltak. Egy, a cím mezőre való korlátozás nélkül végzett keresés (azaz a címben, a referátum szövegében és a deszkriptor mezőben) egyetlen rekordot eredményezett a három legújabb évben; nem kifejezetten erőteljes feltártság.
Az egyes adatbázisokban végzett keresések fényt deríthetnek arra, hogy mennyire felelnek meg a valóságnak a tárgyukra vonatkozó állítások, de a több adatbázisban végzett tesztelés a dolgokat megfelelőbb perspektívába állíthatja. A csak a címek indexében való keresés egyenlő feltételek szerinti keresést biztosít, megszüntetve azokat a különbségeket, amelyeket a referálás és az indexelés különbségei okozhatnak. Nyilvánvaló, hogy az az adatbázis, amely a keresőszót deszkriptorként tartalmazza, több találatot adna, mint az, amely egy szinonimát vagy egy szűkebb fogalmat használ deszkriptorként.
Ennek a tesztnek az abszolút korrektsége érdekében a keresést ugyanarra az időszakra és ugyanarra (ugyanazokra) a nyelv(ek)re kell korlátozni, amelyek az állítások szerint szerepelnek minden adatbázisban. Ha lehetséges, a keresést ugyanarra a dokumentumtípusra kellene korlátozni, mint például folyóiratcikkekre vagy konferencia-előadásokra, megszüntetve a dokumentumtípusok feltártsága különbségeiből adódó eltéréseket. Ezt nehéz elvégezni, mert sok adatbázis vagy nem használ egy dokumentumtípus mezőt, vagy nagyon következetlenül teszi azt.
A LISA adatbázisban például nincs ilyen mező, így a cikkeket, konferencia előadásokat és szemléket nem lehet egyértelműen megkülönböztetni. Az ISA-ban van dokumentumtípus mezőt, de az nem megbízható. Például a konferencia előadások rekordjai "monográfia fejezete"-ként ("monographic chapter") jelennek meg az egyik évben, "monográfia"-ként ("monographic") a következőben, majd 1999-től "folyóiratcikk"-ként ("journal articles"). Meg kell érteni, hogy a nyelv és dokumentumtípus szerinti feltártság, hasonlóan a retrospektivitáshoz, fontos előny lehet egyes használók számára, és ezeket is vizsgálni kell, amikor az adatbázis összetételét és a feltárt időtartományt tesztelik.
Ezeken a megfontolásokon túl sem szabad figyelmen kívül hagyni, hogy néhány kevésbé nyilvánvaló feldolgozási jellemző torzíthatja az összehasonlító eredményeket, mint például azok a különbségek, ahogyan az indexeket építik. Ha olyan összehasonlításokat teszünk, amelyek a címek szavaira vonatkozó kereséseken alapulnak, fontos ellenőrizni, hogy a címindexeket ugyanabból (ugyanazokból) a mező(k)ből építik-e minden tesztelt adatbázisban. Ha az egyik adatbázis a címek indexét a címek és az alcímek mezőiből építi, az torzíthatja az eredményeket. Ha egy harmadik adatbázis a címkiegészítés mezőt vagy almezőt is használja, a különbségek sokkal jelentősebbnek látszhatnak, mint amilyenek valójában. (A címkiegészítések nagyon hasznosak, mert információkat adnak nem kifejező címekre, és segítenek a keresésben és a eredménylisták áttekintésében. Az H. W. Wilson cég például nagyon informatív címkiegészítéseket szolgáltat, ahogy azt a 6. fejezetben tárgyaljuk.) Az időszaki kiadványok címjegyzékei esetében, függően az adatfájl kivitelezésének módjától lehet, hogy a címindex csak a főcímet és a kulcscímet tartalmazza az egyik adatbázisban, míg a másikban tartalmazhatja a korábbi, következő, alternatív, párhuzamos, gerinc- és eltérő címeket.
Hasonló okok magyarázhatják a művészek neve alapján végzett tesztkeresések eredményeinek hatalmas különbségeit zenei címjegyzékekben vagy katalógusokban. A legendás zenészre, Mark Knopflerre vonatkozó keresés 14 találatot ad az Amazon.com-nál (3.8. ábra) és 112-t a Borders.com-nál (3.9 ábra). Az albumok hatalmas számának oka a Borders.com-nál az, hogy ebben megtalálni minden olyan albumot, amelyeken Mark Knopfler vendégművészként szerepelt, mert a művészek indexébe fölveszik a megjegyzések adatmezőt is, amely tartalmaz ilyen információkat. A referáló és indexelő és a teljes szövegű adatbázisok nem problematikusak ebből a szempontból, bár, ahogy korábban említettük, azok az adatbázisok, amelyek kiegészített címeket használnak, mint például az H.W. Wilson adatbázisai, feltétlenül előnyben lesznek a címek szavaira vonatkozó kereséseken alapuló összehasonlítások esetén.

3.8. ábra: A Mark Knopflerre mint művészre vonatkozó keresés eredményei az Amazon.com-nál
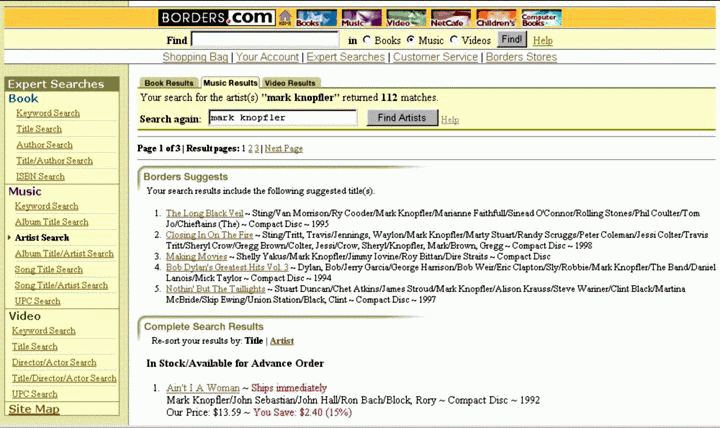
3.9. ábra: A Mark Knopflerre mint művészre vonatkozó keresés eredményei a Borders.com-nál
Az adatbázisok kiadói néha információt adnak arról, hogy a feltárt anyag szempontjából mit tartanak adatbázisuk különös erősségének. Ez azonban nem feltétlenül pontos. Az IFI/Plenum, az Information Science Abstracts korábbi kiadója honlapján (és a DIALOG adatbázis-leírásában és reklámkiadványában) 27 olyan témát sorolt fel, amelyekben "az ISA az Ön elsődleges referensz forrása" (3.10. ábra). Ez az állítás első pillantásra is valószínűtlennek és irreálisnak látszik. Olyan, mintha a Haworth Press azzal kérkedne katalógusában, hogy ő a dinamikus objektum modellekről és az állandó web kapcsolatról szóló könyvek elsődleges forrása.
A lista, amit most revízió alá vettek, csordultig volt divatos frázisokkal, amelyekkel elárasztanak a COMDEX sajtótájékoztatóin. Az adatbázis már nem. Egy keresés olyan divatos szavakra, mint a firewall (tűzfal) és a listserver (két szóként és többes számban is keresve) 2, illetve 3 rekordot adott az egész adatbázisban. A Library Literature-ben és a LISA-ban szintén csupán két rekordja volt, de azok előállítói sohasem állították, hogy listserverre vagy a firewallra vonatkozóan az ő adatbázisuk "az ön elsődleges referensz forrása". Bár az adatbázis új vezetősége kicserélte a tárgyi feltártságra vonatkozó abszurd listát egy elfogadhatóbbal, az sem mentes félrevezető állításoktól, ahogy a korábbi supercomputing példa illusztrálja, és néhány további példa fogja illusztrálni. A kifejezést supercomputingról supercomputersre változtatták az adatbázis átvétele utáni három revízió egyike során, de csak egyetlen árva rekordot adtak hozzá az adatbázishoz erről a témáról, ahogy azt egy későbbi keresés bizonyította, amely a cím, referátum és deszkriptor mezőkben keresett.
Könnyű észrevenni az ilyen extrém blöfföket egy gyors és egyszerű keresés elvégzésével a vizsgált adatbázisban. Több munkát igényel, amikor a téma szerinti keresés nagyszámú rekordot eredményez. A halmaz nagyságát megfelelő perspektívába kell állítani azáltal, hogy összehasonlítható adatbázisokban, összehasonlítható indexekben és összehasonlítható időtartamokra végzünk tesztkereséseket. Azonos feltételek biztosításához az összehasonlítható fontos szó itt. A kulcsszó szerinti keresés - vagy a DIALOG szóhasználata szerint az alapszótárban végzett keresés - egy teljes szövegű adatbázisban nagyságrenddel több találatot ad, mint egy referáló/indexelő adatbázisban. Ugyanakkor egy referáló/indexelő adatbázisban sokkal nagyobb az esély arra, hogy sokkal több, a keresési kifejezés(eke)t tartalmazó rekordot találunk, mint egy csak indexelő adatbázisban.
3.10. ábra: Az ISA divatos kifejezéseket tartalmazó oldala
A deszkriptor mezőben való keresés szintén torzíthatja az összehasonlító keresés eredményeit. Aránytalanul azt az adatbázist részesíti előnyben, amely a keresési fogalmat deszkriptorként használja, szemben azokkal, amelyek bővebb, szűkebb vagy szinonim fogalmat használnak, vagy a tesztkérdésben használt szó helyett eltérő helyesírási formát alkalmaznak. Ez a helyzet például, amikor az egyik adatbázis használja a CD-ROM deszkriptort, míg a másik optical disk (optikai lemez) kifejezést használja, ahogyan az ERIC adatbázis. A hozzáadott értéket tartalmazó elemek, mint például a referátumok és a specifikusabb fogalmak használata nagyon fontos lehet természetesen, de saját jogán kell értékelni, a 10. fejezetben tárgyalt, az indexelés minőségére vonatkozó indexelési feltételek szerint.
Egyes témák esetében az ilyen keresések sem lehetnek tökéletesek. Az amerikai szerzők elsődlegesen a postpartum depression kifejezést használják, európai és brit nemzetközösségből származó szerzők gyakran a puerperal depression kifejezést preferálják. Ebből következően az előbbi kifejezés használata előnyös a MEDLINE számára az EMBASE-zel szemben (amelynek szélesebb az európai forrásbázisa), a második fogalom esetén fordított a helyzet. A puerperal depression kifejezés 352 rekordot talál az EMBASE-ben és csak 22-t a MEDLINE-ban. A postpartum depression kifejezés 149 rekordot talál az EMBASE-ben és 218-at a MEDLINE-ban.
Hasonló okokból a kölcsönzési rendszerre az issue system vagy loan system brit fogalmak használata (s nem az amerikai circulation sytem-é) a LISA-t favorizálná (372 rekord) az ISA-val szemben (87 rekord). A keresésnek a cím mezőre való korlátozása még nagyobb arányú eltérést eredményez: 74 rekordot a LISA-ban és 13-at az ISA-ban. Természetesen ez indirekt módon fényt vet az adatbázisokban feltárt források földrajzi megoszlására, de vannak más megközelítések is erre a célra. Jó kompromisszumot érhetünk el, ha mind a brit, mind az amerikai fogalomra és variációikra is keresünk.
Hogy lemérjük az állítólagos tárgyi feltártságot azokban a témákban, amelyekkel kapcsolatban az ISA azt állította, hogy "az élvonalban" vannak", a DIALINDEX adatbázist használtuk 10 adatbázis összehasonlítására. A DIALINDEX-ben megtalálható az összes adatbázis index fájlja, de maguk a rekordok nem. Ez különösen hasznos adatbázis ahhoz, hogy megtaláljuk a legígéretesebb adatbázisokat bármilyen, néhány kulcsszóval leírható téma esetében. A DIALINDEX a DIALOG-ban található fájlszámok szerint azonosítja az adatbázisokat: INSPEC (2), COMPENDEX (8), ABI/INFORM (15), LISA (61), PASCAL (144), Trade & Industry Database (148), ISA (202), Microcomputer Abstracts (233), Computer Database (275) és Library Literature (438).
A DIALOG rangsorolási számokat ad az adatbázisoknak minden egyes kérdéshez kapcsolódóan. Az 1-es számot kapja az, ahol a legtöbb találat van az adott kérdésre vonatkozóan, 2-t a második legnagyobb, és így tovább. Ha döntetlen van két adatbázis között, akkor a DIALOG a fájlszámok növekvő sorrendjében rangsorolja őket. Például, ha a LISA és az ISA adatbázisokban ugyanannyi találat lenne, s holtversenyben állnának a 6. helyen, akkor a LISA (File 61) kapja a 6-os számot és az ISA (File 202) kapja a 7-est. Ez kis mértékben torzíthatja a rangsort, így az értékelőnek azt lehet tanácsolni, hogy törölje ezt az automatikus rangsorolást, s ugyanazt a ranglista számot adja azoknak az adatbázisoknak, amelyek ugyanannyi találatot adtak.
Az ISA szakterületi listáján szereplő divatos kifejezéseket csak minimális mértékben módosítottuk a kérdésekben, hogy szerepeljenek az egyes és többes számú formák, kötőjeles és egybeírt változatok és a legvalószínűbb helyesírási változatok. A listáról minden második kifejezést kiválasztottunk. Minél magasabb a ranglistaszám, annál rosszabb az adatbázis relatív pozíciója. Az összesített ranglistaszámot úgy kaptuk meg, hogy az egyes kérdések ranglistaértékét összeadtuk. A 3.11. ábra azt mutatja, hogy az ISA (File 202) sohasem érte el az 1-es, 2-es vagy 4-es ranglistaszámot; a 3-as, 5-ös, 6-os és 7-es számot egyszer érte el, a 8-ast kétszer, 9-est és 10-est háromszor. Ezzel a ranglista legaljára került ebben az összehasonlításban, ahol pedig abszolút mértékben rendelkezett a hazai pálya előnyével.
Elmerenghetünk, hogy ez az adatbázis vajon hogyan boldogul olyan szakterületeken, amelyek nem specialitásai. Az ilyen anomáliák természetesen az elemzőt is kíváncsivá teszik, hogy vajon ezek az alaptalan állítások érvényesek-e az egész (adatbázis) családban is. Az IFI/Plenum Mental Health Abstracts (MHA) adatbázisában végzett tesztkeresések alapján úgy tűnik, hogy ott is ez a helyzet.

Összesített pontszám*
Összetett rangsor
* Minél alacsonyabb, annál jobb!
3.11. ábra: A divatos kifejezések eredményének mátrixa
Az MHA "versenytársai" közé a PsycINFO, az EMBASE és a MEDLINE adatbázisok tartoztak. A fájl előállítójának a honlapja itt is megemlít specifikus szakterületeket, ahol "az MHA ismert kiváló feltártságáról" (3.12. ábra)
IFI/Plenum Data Corporation
Mental Health Abstracts
Bibliográfiai adatok a viselkedésről, mentális egészségről és mentális betegségről.
Most elérhető CD-ROM-on.
A Mental Health Abstracts több mint 500000, a mentális egészséggel és mentális betegségekkel kapcsolatos cikk bibliográfiai adatait tartalmazza. Több mint 1000 periodikum cikkeinek referátumait és a hozzájuk tartozó indexfogalmakat tartalmazza, valamint könyveket, kutatási jelentéseket és kongresszusi kiadványokat.
Egyedi feltártság
Ebben az adatbázisban megtalálhatja sok olyan közlemény adatait, amelyek nincsenek benne más adatbázisokban. A Mental Health Abstracts különösen ismert arról, hogy kiválóan feltárja a következő területeket:
- Pszichofarmakológia
- Pszichiátriai kezelés
- A mentális betegségek társadalmi és jogi aspektusai
- Törvényszéki orvostudományi szakirodalom

3.12. ábra: A tárgyi feltártsággal kapcsolatos állítások a Mental Health Abstracts-ben
A tárgyi fogalmakat kis mértékben módosítottuk, hogy lehetővé tegyük a szóvégződések variációit, mint például a psychopharmacolog?, amely visszakeresi a psychopharmacology, psychopharmacologist(s), psychopharmacological stb. szavakat. Az MHA a négy terület közül háromból az utolsó helyen végzett, annak ellenére, hogy ezekben kellett volna a legjobban szerepelnie. Az MHA által két legfontosabbnak mondott szakterületre vonatkozó keresési eredményeket a 3.13. ábra illusztrálja. Az MHA találatainak száma feltűnően alacsony volt, figyelembe véve azt, hogy 1967-ig megy vissza az adatbázis, - sokkal régebbre, mint az EMBASE adatbázis. Amikor a keresést az utóbbi 10 évre korlátoztuk, az MHA számai még lehangolóbbá váltak.
Bár a költségek témáját a 12. fejezetben tárgyaljuk, itt kell megemlíteni, hogy az MHA-nál 150%-kal magasabb volt a kapcsolati idő díja, mint a PsycINFO-nál, és a nagyon jól teljesítő MEDLINE adatbázis már elérhető volt ingyen is (bár nem a DIALOG-nál). Újra csak azt lehet mondani, hogy a régi bölcsesség, miszerint azt kapod, amiért fizetsz, gyakran nem érvényes az adatbázisokra. Az sem jelenthet sokat, hogy a fájl előállítójának neve milyen elismertségnek örvend más területeken. Az IFI/Plenum anyacége például tekintélyes kiadó. Hasonló módon az Elsevier a tudományos folyóiratok legnagyobb kiadója, de Scirus címjegyzéke, amely minden oldalán azt állítja, hogy "csak tudományos információ"-ra szolgál, a használókat felületes és teljesen vulgáris weblapok tízezreihez vezeti el, ahogyan azt a http://www2.hawaii.edu/~jacso/extra/ címen láthatjuk illusztrálva.
A szerzőnek ezen a weblapján találhatnak egy illusztrált útmutatót is a Claritas drága Population Demographics adatbázisának nonszensz adataihoz. A statisztikai adatok, amelyek csaknem 6000 nulla lakosú települést tartalmaznak, különös statisztikai mérésekre utalnak, hogy mértéktartóan fogalmazzunk.
Ilyen tesztek több olyan témában elvégezhetőek, amelyek a célközönség elsődleges érdeklődéséhez kapcsolódnak. Ez azt a benyomást adhatja, hogy az adatbázis tárgyi feltártsága pertinens egy meghatározott használó vagy használói csoport számára - függetlenül attól, hogy mi a tesztelt adatbázis állítólagos tárgyi feltártsága. Ha valaki meghatározott szakterületen ismeri a használói közönség preferenciáit, a tesztkeresések könnyen korlátozhatóak időszakra, a kiadás országára vagy nyelvre.
Például a humán tudományok kutatói ismertek arról, hogy a számítógéptudósoknál jobban kedvelik a 10-15 évvel ezelőtt kiadott könyveket; ezért a tesztek módszereit a szakterületet és a megcélzott használói csoportok igényeihez kell igazítani. Ezt illusztrálják az 5. fejezetben az adatbázis dimenzióira és a feldolgozott forrásdokumentumokra vonatkozó részek a kiadványok megjelenésének országa és nyelve szempontjából.

3.13. ábra: A DIALINDEX-ben végzett keresések eredményei
Az ilyen típusú tesztelés a DIALOG, DataStar és WebSPIRS rendszerekben a legkönnyebb, mivel speciális parancsaik és adatbázisaik vannak arra, hogy egyszerre az összes adatbázis indexében keressenek. A DIALOG ezt DIALINDEX-nek hívja, a DataStar CROS-nak, s a WebSPIRS-nek is van speciális funkciója (Find Database) az ilyen keresések elvégzéséhez (3.14. ábra)

3.14. ábra: A Find Database funkció a WebSPIRS-ben.
A keresés elvégezhető több adatbázisban anélkül is, hogy a közös indexben keresnénk, de ez természetesen tovább tart és többe kerül. A DIALOG megkönnyíti az ilyen több fájlban történő keresést azzal, hogy közel 500 adatbázisát egy vagy több tárgyi csoportba sorolja be. Ezeknek a csoportoknak saját neve van, mint például PSYCHOLOGY és LIBRARY AND INFORMATION SCIENCE. A csoportok nevének rövidített változata (PSYCH és INFOSCI a mi példánkban) használható mind a DIALINDEX-ben, mind a OneSearch keresésekben. Az utóbbi a keresést a csoport által meghatározott valódi adatbázisokban végzi el.
A felhasználókat figyelmeztetni kell arra, hogy ne bízzanak kizárólagosan a DIALOG előre meghatározott tárgyi adatbáziscsoportjaiban, mert azok gyakran tartalmaznak majdnem teljesen irreleváns adatbázisokat s hagynak ki nagy mértékben relevánsakat. A pszichológia szakterületén például a DIALOG PSYCH adatbáziscsoportja felsorolja a British Education Indexet, a National Technical Information Service (NTIS) adatbázist és a A-V Online-t - nem kifejezetten olyan adatbázisok, amelyekről az embernek eszébe jut a pszichológia.
A DIALOG ugyanakkor kihagyja ebből a csoportból a nagymértékben releváns MEDLINE és EMBASE adatbázisokat (3.15. ábra). Amikor valaki a józan eszét használja az adatbázisok kiválasztásában és a keresőkérdés megfogalmazásában, az ilyen tesztkeresések jó kiindulópontot adhatnak ahhoz, hogy továbbmenjünk az értékelésben és megvizsgáljuk az adatbázisok más jellegzetességeit, méretüket és összetételüket, feltárt forrásaikat és aktualitásukat.

3.15. ábra: A rosszul meghatározott PSYCH adatbázis csoport a DIALOG-nál.



