
4. Az adatbázis dimenziói
Egy adatbázisról szerzett első benyomásunk nem különbözik attól, amit egy emberről szerzünk. Ahogy elsőre észrevesszük, milyen magas, milyen nagy és milyen idős az a személy, az első kiadói reklámból is megtudjuk, milyen nagy az adatbázis és időben meddig megy vissza. Ahogyan téves lehet egy személlyel kapcsolatos, rövid találkozáson alapuló első benyomásunk, ez lehet érvényes egy adatbázissal kapcsolatos első benyomásunkra is. Ezek a jellemzők fontosak lehetnek, de csak akkor, ha az ember a maga összefüggésében látja, hogyan számították ki a gusztusos brosúrákban büszkén jelentett méreteket, s mi van azok mögött a számok mögött, amelyekkel egy adatbázist le akarnak írni.
Méret és összetétel
A rádiók és televíziók reklámjai, a nyomtatásban megjelent hirdetések és a Guinness rekordok könyve ahhoz szoktathatott hozzá sok embert, hogy azt higgye, hogy ami nagyobb, az jobb is. Nem véletlen, hogy az adatbázisokat hirdető anyagok is elsősorban az adatbázis méretével kapcsolatos állításokat állítják előtérbe. A józan ész azonban arra figyelmeztet, hogy a legnagyobb nem egyenlő a legjobbal. Lehet, hogy Oroszországnak van a legnagyobb kereskedelmi repülőgép flottája Európában, de légitársasága a legrosszabbak közé tartozik a biztonság, kényelem, a szolgáltatás minősége és a pontosság szempontjából. A legnagyobb tengeri különlegességeket hirdető étteremben nem szükségszerűen a legjobb tintahalat, osztrigát, garnélarákot szolgálják fel. Sok múlik természetesen az egyedi preferenciákon abból a szempontból, hogy mi teszi a tengeri specialitások éttermét a legjobbá, de az étterem mérete nem feltétlenül alapvető követelmény. Ugyanez érvényes az adatbázisokra is.
A legnagyobb orvosi adatbázis, amely nem dolgozza fel Kelet-Ázsia folyóiratait a megfelelő mértékben, nem lehet a legjobb annak a számára, aki ennek a régiónak a fejlődéséről vagy klinikai jelentéseiről keres információt. A legnagyobb cégjegyzék kevés értékkel bírhat egy olyan cég számára, amely üzletének nagy részét Kelet-Európa országaival bonyolítja le, ha az adatbázis nem tartalmazza Lengyelország, Magyarország, Szlovákia, Csehország és Románia cégeit.
Elég beszédes az adatbázis méretére vonatkozó megszállottsággal kapcsolatban, hogy a Barnes & Noble perrel fenyegette meg az Amazon.com-ot, mert az a világ legnagyobb webes könyvesboltjának mondta magát. Az Amazon.com valóban sok webhasználót megnyert a maga számára úttörő vállalkozásával, első osztályú szoftverével és kiváló szolgáltatásaival, sokkal hamarabb, mint hogy a Barnes & Noble-nak egyáltalán eszébe jutott volna a webre menni, bár most az utóbbi jogosan büszkélkedik az exkluzív "a világ legnagyobb online könyvkereskedője" szlogennel. Mihelyt a Barnes & Noble, ahelyett hogy a jogászai által kezelt dolgokat pénzelné, elkezdett áldozni a jó programozásra és figyelmét a méret helyett más kérdéseknek szentelte, rendkívüli mértékben növelte adatbázisa tartalmának funkcionalitását. Időközben az Amazon.com kiterjesztette tevékenységét sok területre, a játékoktól a konyhai edényekig, ugyanakkor könyvadatbázisának mérete sem menthette meg részvényárainak zuhanásától.
Elég sokat mond el a mérettel kapcsolatos rögeszmékről az, hogy a Northern Light keresőgépében végzett keresés 11153 olyan weblapot talált, amely tartalmazza a largest database (a legnagyobb adatbázis) kifejezést. Az eredménylista első oldala alapján olyan weboldalak tartalmazzák a legnagyobb adatbázis kifejezést, mint 1, éttermek listája, 2, igehirdető és tanító videók, 3, kölcsönzők Oregonban, 4, partiképes agglegények, 5, thaiföldi ingatlanok, 6, magánhirdetések és 7, ejtőernyős vízisízéssel kapcsolatos információk. Maga a largest (legnagyobb) szó több mint 4,6 millió oldalon fordul elő, eszerint a - nos - legnagyobb keresőgép szerint.
Az adatbázis mérete ennek ellenére hasznos indikátor lehet, ha pontosan és megfelelő összefüggésben értelmezik. Ezt az információt általában könnyű megszerezni a kiadótól vagy magából az adatbázisból. Mindig jobb az adatokat az adatbázisból kinyerni, mint az esetleg már elavult dokumentációból. A legtöbb DIALOG adatbázisban a (tervezett) aktualizálási dátumot hozzáadják a rekordhoz; ezért egy teljesen csonkolt keresés (S UD=?) meg fogja mutatni az adatbázis pillanatnyi méretét. A SilverPlatter szoftverét használó adatbázisokban nincs meg a teljes csonkolási lehetőség, de a FIND UD>0 parancs meg fogja adni a rekordok teljes számát. A 4.1 ábra megmutatja annak a keresésnek az eredményét, amely meghatározza az Information Science Abstracts (File 202), Library and Information Science Abstracts (File 61) és Library Literature (File 438) méretét, az S UD=? keresőkérdés alkalmazásával. Az eredmények ennek a három adatbázisnak a méretét tükrözik 1999 utolsó hetében.
4.1. ábra: Három könyvtár- és információtudományi adatbázis mérete
Egy multidiszciplináris adatbázisban is meg lehet határozni egy megfelelő részhalmaz méretét, ha van olyan adatelem, amely egyértelműen azonosítja a részhalmazt. Ez a helyzet a Social SciSearch adatbázis (File 7) és a Trade & Industry Database (File 148) esetében. A 4.2 ábra megmutatja, hogy ezeknek az adatbázisoknak a könyvtár- és információtudományi részhalmaza összehasonlítható a három előző adatbázissal. A Bell & Howell szintén jól feltárja a könyvtár- és információtudomány irodalmát az ABI/INFORM és a Periodicals Abstracts PlusText adatbázisokban, de egyik sem határozza meg a kategóriát, amelyhez a rekordok tartoznak, ennélfogva nem lehet megállapítani ezen adatbázisok könyvtár- és információtudományi részhalmazának méretét.

4.2. ábra: Az információ- és könyvtártudományi részhalmaz méretének megállapítása
a Social SciSearch és a Trade & Industry adatbázisokban
Azokban az adatbázisokban, amelyeknek nincs külön meghatározott aktualizálás mezője, más technikákat kell alkalmazni. A legtöbb adatbázisban általában van néhány olyan adatelem, amely nagy valószínűséggel minden rekordban megtalálható, s ezek értékeinek száma korlátozott. A Bowker cég címjegyzékeinek saját változatában használt szoftverben nincs aktualizálás mező, de vannak más adatmezők, amelyekről feltételezni lehet, hogy minden rekordban jelen vannak. Például az Ulrich's adatbázisban (Ulrich's International Periodicals Directory) a periodikum státusza aktív, megszűnt vagy nem igazolt lehet (active, ceased és unverified), ezért az SS=$ keresés valószínűleg a rekordok teljes számát eredményezi. A Bowker Who's Who adatbázisaiban a felvett személyek neme jó keresési kritérium lehet az adatbázis méretének meghatározásához. Elég biztosan feltételezhető, hogy a benne szereplő személyek vagy férfiak, vagy nők, minden rekordnak van a nemre vonatkozó információja, még akkor is, ha esetleg ez az adat "nem igazolt" (unverified) vagy "meghatározatlan" (undetermined). A használókat figyelmeztetni kell arra, hogy sok adatbázisban rekordok tízezreiben nincs meg a feltételezett adatelem, ahogy azt majd a 9. fejezetben a rekordok teljességére vonatkozóan megtárgyaljuk.
A teljes csonkolás működhet olyan mezők esetében is, amelyek gyakorlatilag mindig jelen vannak, mint például a cím mező, de nagyon hosszú időbe telhet egy TI=$ vagy hasonló keresés végrehajtása a Bowker saját CD-ROM implementációiban, mert az egyedi tételek száma egy nagy adatbázisban több millió is lehet. Elvégezhető azonban, s jelen szerző el is végezte egy gyors számítógéppel és a szoftver gyors windowsos változatával, ahogy azt a 9. fejezet illusztrálja. Előre figyelmeztetjük, hogy a DOS-os verzióban a képernyő lefagyhat meghatározott mennyiségű inaktív idő után; azaz a keresés befejeződhet, míg a kereső távol van.
Számos adatbázisban vannak mezők két értékkel, például angol és nem angol nyelvű, magán vagy állami cégek, vagy egy pszichológiai adatbázisban a populáció Human és Animal (emberre és állatra vonatkozó) lehet. Ha ezeket következetesen hozzáadják minden rekordhoz, akkor a méret meghatározható egy egyszerű OR-ral összekötött keresőkérdéssel ebben a mezőben: S LA=(English or Non-English). Azok a CD-ROM adatbázisok, amelyek a Dataware Technologies szoftverét használják (mint például a Historical Abstracts), általában képesek none és az all (egyik sem, mind) keresőfogalmat használni egy mezőre, s ezzel is meghatározható egy adatbázis mérete. Szoftverének buildware-összetevője generálja ezt a két speciális indextételt minden indexelt mezőre.
Ha egy rekordban mondjuk a kiadási év jelen van, akkor a kiadási év indexének all pszeudo indexében található tételek száma növekszik eggyel. Ha a mező hiányzik, akkor a pszeudo index none tételeinek száma növekszik eggyel. Ugyanez történik minden indexelt mező pszeudo index tételeivel. Mivel ezeket az index tételeket akkor generálják, amikor az adatbázist létrehozzák, a kereséshez csak egy másodpercre van szükség, amikor előbb az all, azután pedig a none keresést végezzük el, akár még a cím mező esetében is.
A legtöbb olyan keresőszoftver, amelyet közvetlenül a web számára fejlesztettek ki (ahelyett, hogy átvitték volna a hagyományos online változatból), nem ajánl fel lehetőséget az adatbázis méretének meghatározására a fenti módszerek valamelyikével. Bár a kiadási év kereshető, általában nem alkalmazható magában, hanem csak korlátozó mezőként egy tárgy vagy szerző szerinti keresést kiegészítve. Például akkorának kell elfogadnunk az adatbázisok méretét, amit az Amazon.com és a Barnes & Noble állít magáról.
Bár az Amazon.com esetében a Kiadó/Dátum keresési űrlap lehetővé teszi egy meghatározott év előtt, során vagy után kiadott könyvek keresését, amikor a 2001 előtt (before 2001) opciót önmagában választjuk, az az üzenet jön válaszként, hogy a kiadó nevét vagy egy kulcsszót is meg kell adni. Hasonló módon a Barnes & Noble is felajánlja a keresést három árkategória szerint, s ugyanígy média típusa szerint (papírkötésű, keménykötésű, nagybetűs, audiokönyv), amelyek tökéletes jelöltek lehetnek az adatbázis méretének meghatározására. Sajnos ezek a keresési feltételek csak egy címhez, szerzőhöz vagy tárgyhoz kapcsolódó korlátozóként használhatóak.
Önmagában nem elég, ha ismerjük az adatbázis méretét. Ezt a számot az adatbázis összetételének függvényében kell vizsgálni. Ahhoz, hogy egy adatbázis sokatmondó méretét megítéljük, tudnunk kell, hogy a rekordokat milyen egységek számára hozták létre. A G. K. Saur World Databases címjegyzéke (WDNBS) egy rekordot hoz létre minden adatbázis minden egyes változatára - plusz még egy mester rekordot. Ez felduzzasztja a rekordok számát a World Databases adatbázisban. A Gale cég Directory of Databases adatbázisában új rekordot képez minden egyes médiumra, amelyben az adatbázis megtestesül (azaz egy rekord van a mágnesszalag változat(ok)ra, egy a CD-ROM változat(ok)ra és egy az online változat(ok)ra, de nincs külön-külön rekord minden egyes CD-ROM vagy online változatra).
A Mental Health Abstracts adatbázis esetében a Gale címjegyzékében egy rekord van az adatbázis online és egy másik a CD-ROM változatára (4.3. ábra). A WDBS-ben külön-külön rekord van a CompuServe-en, a Westlaw-n és a DIALOG online adatbázis változaton, plusz egy mester rekord (4.4. ábra). Ez nagyon felhígítja az adatbázis méretét, különösen azért, mert a Compuserve és a Westlaw is a DIALOG-nak passzolja a keresőkérdést, hogy ezt az adatbázist szolgáltassa. Mellesleg a WDBS nem tud az MHA adatbázis CD-ROM változatának létezéséről.

4.3. ábra: Az MHA adatbázis online és CD-ROM változataira
egy-egy rekord található a Gale címjegyzékében
A másik komoly és fontosabb következmény, hogy sokkal drágább a G. K. Saur adatbázisában keresni, ahol minden egyes rekord megjelenítése négy dollárba kerül és az ingyenes találati lista semmi információt nem ad arról, hogy melyik rekord melyik változatára vonatkozik (4.4. ábra). Egy kitalálós játék az, ahogy megjeleníti az MHA adatbázis DIALOG, Westlaw vagy Compuserve változatának rekordjait.
Tovább növeli a gondot, ha az ember rájön, hogy mennyire hihetetlenül pontatlanok az információk a World Databasesben, s hogy nagyrészt ugyanazt a nonszensz információt viszik át egyik rekordból a másikba, egyenként négy dollárért. Ez a helyzet akkor, amikor minimális szerkesztői odafigyelés vagy hozzáértés elég lett volna a legszembetűnőbb hibák észrevételéhez, mint egy adatbázis részhalmazának kiadása esetében. Nagyon gyakran a rekordok közötti egyetlen különbség a fájl és a terjesztő neve.
A WDBS azt állítja az MHA-ra vonatkozó mind a négy rekord esetében, hogy minden frissítéskor 18000 rekorddal egészítik ki az adatbázist. A szám önmagában is abszurd, s ezt propagálják olyan módon, hogy átviszik az MHA adatbázist leíró egyik rekordból a másikba (4.5. ábra). A pontos szám körülbelül 300 frissítésenként, ahogyan azt a Gale címjegyzéke megadja, s ahogy azt az MHA aktualizálási indexének böngészése is igazolja.

4.4. ábra: Az MHA online változatainak négy rekordja a World Databasesben.

4.5. ábra: Abszurd információt visznek át egyik rekordból a másikba a World Databasesben.
A leírás egységeire vonatkozó ésszerűbb és hagyományosabb döntések is jelentős különbségekhez vezethetnek az adatbázis méretében. Ahogy azt az előző fejezet illusztrálta, az Ulrich's adatbázisban a Bowker a legújabb tétel elvét alkalmazza egy rekord megalkotására minden egyes időszaki kiadvány esetében. Ez azt jelenti, hogy ha egy időszaki kiadvány címe megváltozik, a korábbi cím rekordját törlik és a releváns elemek (cím és ISSN) bekerülnek az új rekordba. Ezzel ellentétben az EBSCO az egymást követő tételek elvét követi, s külön rekordot alkot minden egyes időszaki kiadványra, amelynek a címe megváltozott, s megtartja a korábbi címhez tartozó rekordot is.
Jelentős különbség van abban, hogyan kezelik az adatbázisok azokat a szemlecikkeket, amelyek több műről tartalmaznak kritikát. Például az EContent (korábban Database címen volt ismert) "Péter's Picks and Pans" rovatában mindig három vagy négy adatbázist ismertet. Ezt a rovatot több adatbázis feldolgozza, közte az ABI/INFORM, a Trade & Industry Database, a Periodical Abstracts PlusText, a Social SciSearch és az ISA. 1997-ig a legtöbb adatbázis egyetlen rekordot készített az egész szemlecikkről.
1997 óta azonban a Social SciSearch kezdett külön rekordot alkotni minden egyes bírált műről, és sok más fájl előállító is átváltott erre a rendszerre (ABI/INFORM, Trade & Industry Database és Periodical Abstracts). 1999-től az ABI/INFORM visszatért a cikkenkénti egy rekord elvéhez. A Trade & Industry Database 1999-ben három rekordot készített az év első rovatának három kritikájához, de csak egyet a másodikhoz. Mások, mint az ISA és a LibLit, megmaradtak a cikkenkénti egy rekord elvénél, amely hátrányba hozza őket a fájl méretének összehasonlításakor, különösen akkor, amikor egy folyóirat feltártságának mélységét hasonlítják össze.
Ez különösen igaz a Wilson adatbázisokra, amelyekben számos szemlecikk szerepel egyetlen rekorddal cikkenként, nem külön rekorddal a cikkben kritizált minden egyes műről. Például a Readers' Guide Abstractsben több mint 220000 rekord van könyvkritikákból. Sok szemlében több mint egy műről jelent meg kritika, de mivel az H. W. Wilson nem hígítja fel adatbázisa méretét azzal, hogy minden egyes kritizált műről egy rekordot hoz létre, a használóknak nem kell többet fizetnie az idő és különösen a tételenkénti megjelenítés és nyomtatás miatt minden egyes rekord visszakeresésekor.
A szemlecikkek különböző és következetlen kezelése magyarázza meg a keresési eredmények furcsaságait a 4.6. ábrán. A LibLit (File 438) és az ISA (File 202) 1999-ben az első két cikket egy-egy rekordként dolgozta fel. A Trade & Industry Database (File 148) három rekordot hozott létre az első, egyet a második cikkre. A LISA (File 61) nem dolgozott fel egyetlen szemlecikket és egyetlen cikket sem 1999-ben a Database-ből egészen az év júliusáig (ez volt az utolsó szám ez alatt a cím alatt). Az ABI/INFORM (File 15) egy rekordot készített 1999 mindhárom szemlecikkére. A Social SciSearch (File 7) összesen 9 rekordot alkotott, egyet-egyet mindhárom cikk három-három kritikájára. Ez apró pont az adatbázisok rekordjainak százezrei között, de amikor a feldolgozottságot a szerzők vagy a folyóiratok szintjén hasonlítjuk össze, a különbség jelentős lehet.

4.6. ábra: A szemlecikkek feldolgozási különbségeinek hatása.
A rekordok teljes száma a Bowker's Complete Video Directoryban félrevezető lehet, ha nem tudjuk, hogy számos rekord van ugyanarról a filmről. (4.7. ábra). Egyes rekordok nyilvánvaló kihagyásain és következetlenségein (mint például az MPAA osztályzatai vagy Gene Wilder mint az elsődleges közreműködő a találati listán), az ár és a rögzítési formátum (VHS kontra Betamax) különbségein kívül néhány megháromszorozott vagy megnégyszerezett rekordban az eltérések ugyannak a filmnek fél tucat másik rekordjában csupán lényegtelen apróságok. Ezek a részletek csak videókereskedők számára lehetnek érdekesek, de nem egy audiovizuális könyvtár ügyfelének, ahol ezt az adatbázist gyakran használják. Még ha ezek a különbségek netán mégis fontosak (mint például a rögzítési formátum), jobb lenne egyetlen rekordot létrehozni, amely a különböző kiadások mindenféle sajátosságait szerepeltetné. A 0,00 dolláros ár nagyon vonzó, de nem igaz.
Ez a megközelítés nem felel meg az angol-amerikai katalogizálási szabályoknak (AACR2), de a címtár adatbázisoknak nem kell követniük azokat a szabályokat, amelyeket azért hoztak létre, hogy a könyvtárak adott állományához való hozzáférés eszközei legyenek. Dicséretre méltóan a Bowker elkezdte alkalmazni ezt a közös rekord koncepciót Books in Print (BIP) adatbázisának saját CD-ROM változatában, ahol a különböző kiadásokat és kötésváltozatokat egyetlen rekordon belül sorolják fel. Bár ez csökkentette az adatbázis méretét, a használóknak előnyére szolgált, és - ismételjük -, az AACR2 szabályok nem érvényesek a címtárak tételeire. Az információ rendezése egyetlen rekordban egyszerűsítette a keresés folyamatát. Sajnos a BIP online verzióinak nem minden kiadója követte ezt a gyakorlatot, azon használók kárára, akikre a tranzakciónkénti díjszabás érvényes. Nekik minden egyes rekordért fizetniük kell még akkor is, ha a lényeges információk (cím, szerző, kiadó stb.) alapvetően ugyanazok.

4.7. ábra: Több rekord ugyanarról a filmről a Bowker cég Complete Video Directoryjában.
Az Internet Movie Database mutatja a legelegánsabb és legtisztességesebb megoldást ugyanazon film több változatának a kezelésére. Egy visszakeresett rekord van az Annie Hallról (4.8. ábra), s az értéknövelt információkat tartalmazó mezők tucatjai között van egy közvetlen linkkel kapcsolt alrekord, amely akkor jelenik meg, ha a film DVD kiadásának opcióját választjuk (4.9. ábra)

4.8. ábra: Az Annie Hall mesterrekordja az Internet Movie Database-ben.

4.9. ábra: Az Annie Hall DVD-specifikus információjának kapcsolódó rekordja.
Bár az adatbázis méretének felduzzasztása sokszor rosszul elgondolt vagy legalább vitatható koncepción alapszik, a duplikált rekordok jelentős száma a gondatlan vagy hozzá nem értő menedzsment (vagy mindkettő) jele az adatbázis építésében, és a használó figyelmen kívül hagyásáról árulkodik. A CD-ROM-os film címjegyzékek közül a Cinemania messze a legjobb kiváló tartalma alapján, különösen Roger Ebert, Leonard Maltin és Pauline Kael elsőrangú szemléinek köszönhetően. A Microsoft nem duzzasztotta fel az adatbázis méretét azzal, hogy minden kritikához külön rekordot hozott létre. Ezek magának a filmnek az egyetlen mesterrekordjához vannak kapcsolva hiperlinkekkel.
A Corel cég gyatra film címjegyzékében büszkén hirdette magáról, hogy 90000 rekordot tartalmaz, ám elmulasztotta megemlíteni, hogy számos rekord duplikátum vagy akár harmadik rekord, eltérő információkkal a közreműködők listájáról, a film hosszáról és más adatelemekről. Ezen felül a filmek osztályzatai és kritikái szemmel láthatóan olyanoktól származnak, akiket az unalmas "Akarsz napi 300 dollárt keresni filmnézéssel?" szövegű, a buszmegállókba kiragasztott hirdetésekkel toboroztak. Ennek az adatbázisnak az alacsony színvonala annak tulajdonítható, hogy a Corelnek hiányzott a gyakorlata az adatbázis-építésben; néhány évvel később abba is hagyták ezt a tevékenységet.
Különösen frusztráló, ha a használó rájön arra, hogy egy referáló és indexelő adatbázis méretét nagy mértékben megduplázott és megháromszorozott rekordok növelik, ahol nincs is olyan lehetséges kifogás, amely a címjegyzékek esetében talán elfogadható. Még lehangolóbb volt, amikor egy professzionálisnak gondolt adatfájl készítő (például az IFI/Plenum) készített egy fájlt, a könyvtárosoknak és más információs szakembereknek szánt Information Science Abstractset, amely tele volt ugyanarról a cikkről második és harmadik rekordokkal. Erről az adatbázisról készült kritikájában Jacsó (1997e) becslése szerint - amely tesztkereséseken alapult - körülbelül 12000 duplikált pár volt az adatbázisban (és a nyomtatott változatban is).
Bár más adatbázisokban is vannak duplikátumok, ez az arány példa nélküli egy olyan adatbázisban, amely 200000-nél kevesebb rekordból áll. Nagyon nyugtalanító volt, hogy az adatbázis készítőjének fogalma sem volt a duplikátumokról. A cég alelnöke, aki hosszú időn keresztül az adatbázis szerkesztője is volt, azt állította "1987 óta, amikor az IFI átvette az előállítását és kifinomult duplikátum detektáló rendszert kezdett alkalmazni, a duplum és triplum rekordok előfordulása megszűnt" (Allcock 1997).
Valóban így történt? Egy egyszerű ellenőrzés (4.10. ábra, a DIALOG IDO (Identify Duplicates Only, csak a duplikátumok azonosítása) parancsa megmutatta, hogy ez az állítás nem alapulhatott tényeken vagy a valóságon. Az ASLIB Proceedingsből származó 67 1990-es cikkek közül 30 (a duplikált párok 60 rekordjából) volt duplikátum. 1991-ben 76 rekordból is 30 duplikátum volt, egy pedig háromszor szerepelt.

4.10. ábra: A duplikátumok detektálásának eredményei
A DIALOG duplikátumokat felderítő algoritmusa nagyon jó, de nem tökéletes, ennek eredményeit nem lehet teljes mértékben elfogadni. Csak a szerzői és a cím mezőt ellenőrzi. Ennek a módszernek a következményeként azokat a tételeket, amelyek egy rendszeresen megjelenő rovathoz tartoznak, s így közös címük van, de nincs megkülönböztető alcímük (mint például a Savvy Searching), duplikátumoknak fogja tekinteni. A könyvkritikák rekordjain gyakran egyszerűen a "Book review" cím szerepel. Az ugyanattól a szerzőtől származó könyvkritikák így duplikátumnak fognak minősülni, pedig nem azok. Az emberi szem számára nyilvánvaló, hogy a kötet, szám vagy oldalszám egyértelműen megkülönbözteti az egyik szemlét a másiktól, de a DIALOG duplikátumokat felderítő algoritmusa nem ellenőrzi ezeket az adatelemeket. Az is lehetséges, hogy ugyanaz a szerző publikálta ugyanazt a cikket egy másik folyóiratban, ami nem igazán okos dolog, de mindkettőre külön rekordot kell felvenni. Másrészt a valódi duplikátumokat a program nem találja meg, ha a címet nem ugyanúgy írták át ugyannak a cikknek a két rekordjában. A brit és amerikai helyesírási különbségeket jól kezeli az algoritmus, ahogyan a központozás kis különbségeit is, de nem minden alapszó szerepel a valódi duplikátumok megállapításához. Az értékelő számára a duplikátumokat felderítő keresésre feltehetőleg az a leghatékonyabb módszer, ha néhány kiválasztott folyóirat alapján végzi a tesztelést.
Minden egyes duplikátum vizuális ellenőrzése mellett más módszer is van a duplikátumokra vonatkozó jelentések megbízhatóságának ellenőrzésére. Például abban az esetben, amikor az ASLIB Proceedings a tesztelt folyóirat, az INSPEC, a Library and Information Science Abstracts és a Social SciSearch adja az ISA legjobb kontroll csoportját. Ha igaz az a feltételezés, hogy a DIALOG szoftvere hibásan azonosítja a duplikátumokat bármelyik korábban említett okból, akkor ennek minden olyan adatbázisban meg kell mutatkoznia, amely ugyanazt a folyóiratot feldolgozza. A 4.11. ábra világosan megmutatja, hogy nem ez a helyzet. A kontroll csoportban csak a Social SciSearchben van duplikátum, ott is csupán egyetlen pár. Az ISA 224 rekordjából 156 duplikátum pár része.

4.11. ábra: Duplum-eredmények ellenőrzése kontroll-csoportokkal.
Az ISA WinSPIRS változatából vett példák annak tömörebb outputjával (4.12. ábra) egyértelművé teszik, hogy ezek valóban olyan rekordok, amelyeket kétszer vagy háromszor vittek be az ISA-ba, így például a Key Technologiesról szóló cikk esetében, ahol elírt alcímeket találhatunk. Az adatok bevitele évének elemzése rekordok ezreiben jelezte, hogy a duplikátumok nagy százalékát vitték be 1987 után, pedig ez volt az az év, amelyről a szerkesztő azt állította, hogy a duplikátumok hozzáadása megszűnt. A tipikus minta erre a folyóiratra és a legtöbb duplikátumra az, hogy a duplikátumok az első rekordok után három évvel kerültek be az adatbázisba. Ezek nélkül a duplikátumok nélkül az adatbázis nem mutatott volna következetesen és kereken 800 rekordot a legtöbb aktualizáláskor 1995-ben.
Az új fájl producer elsőbbséget adott a duplikátumok és a háromszoros rekordok kiszűrésének, eltávolításának, de még mindig elég maradt 2000 végére, hogy az esetet az ISA DIALOG -os online változatából illusztrálni lehessen. (4.13. ábra)

4.12. ábra: Részlet az ISA duplikátumainak listájáról

4.13. ábra: Még mindig maradtak duplikátumok az ISA-ban.
Más online és CD-ROM keresőprogramok nem teszik lehetővé a duplikátumok felderítését (kivéve az Ovidot, amely 1999-ben egészítette ki szoftverét ezzel a lehetőséggel), de azok, akik letöltenek rekordot egy bibliográfiai információkat kezelő szoftverbe (például a Reference Managerbe vagy a ProCite-ba) használhatják ezeknek a programoknak a testre szabható duplikátum felderítő tulajdonságát. Az ISA webes változatának most megszűnt, használó-orientált Search-by-Search verziójában a duplikált és háromszoros rekordok megjelenítése és kinyomtatása nagy gondot jelenthetett az alkalmi használóknak, akik tipikusan saját zsebből fizetnek. Nem csoda, hogy ez a szolgáltatás rövid idő alatt megszűnt.
Az adatbázisok CD-ROM-változatában a duplikátumok nem jelentenek zsebbevágó kiadásokat, de plusz munkát igényel a duplikátumok eltávolítása az eredmények végső listájáról. Természetesen jelzéssel is szolgálnak az adatbázis minőségéről. 15 évvel az adatbázis készítésének megkezdése után, 1998-ban a Documentation Abstracts, Inc. felbontotta szerződését az IFI/Plenummal, és az adatbázis előállítása az IFI/Plenumtól az Information Todayhoz került át.
Sajnos még mindig kerülnek be új duplikátumok a rendszerbe, ahogy azt a 4.14. ábra mutatja. Ez a helyzet megkérdőjelezi a duplikátumok felderítésének hatékonyságát. A duplikátumok terhet jelentenek a használók számára mind időben, mind pénzben kifejezve. Vegyük észre, hogy nem csak a deszkriptorok, hanem még a széles tárgyi csoportok is különböznek a duplikátumok párjaiban. A nyomtatott változatban a rekordok listáját a széles tárgyi csoportok szerint rendezik, a duplikátumok nem jönnek elő ugyanabban a kategóriában, így a használónak nincs déja vu érzése. Az online és a CD-ROM-változatok használóinak biztosan van.

4.14. ábra: Újabban hozzáadott duplikátumok.
Vannak további fontosabb szempontok, amelyek hatással lehetnek arra, hogy valaki hogyan értékeli egy adatbázis megfelelőségét, mint például a feldolgozott dokumentumok típusa és nyelve, a szereplő cikkek típusai, a magfolyóiratok felvételének mértéke, a rekordok időbeli eloszlásának aránya. Ezek a szempontok önmagukban is érdekesek, s a következő részekben tárgyaljuk őket.
Időbeliség
Az adatbázisok jelentős mértékben különböznek feltárt anyaguk retrospektivitásában. Önmagában semmi rossz nincs abban, ha egy adatbázis rövid időszak anyagát tárja fel, a nagyon hosszú időtartam sem feltétlenül erény, ez a használók preferenciáin és az adatbázis jellegén múlik. Számos online rendszerben alapbeállításban a kereshető időtartam a kurrens év és az azt megelőző két év. Ez azt sugallja, hogy a legtöbb használót a két vagy három évtől nem régebbi cikkek érdeklik. 1998-ban a UMI (most Bell & Howell) bevezette a Newsstand adatbázisát, az induló év 1998 volt. Bár ez szokatlanul rövid retrospektív feltártság a referáló és a teljes szövegű adatbázisok között, az adatbázis célja - ahogy arra neve is céloz - az, hogy elektronikus újságosstand legyen. Ez sokkal retrospektívabb, mint a valódi újságosstandok, ahol csak a folyóiratok, magazinok és napilapok kurrens száma található meg. A Newsweek adatbázis változatának megindulása 2000 februárjában bármilyen visszamenőleges anyag (back file) nélkül azonban mindenesetre túl extrém volt egy egyetlen forrást tartalmazó adatbázis számára.
A Ziff-Davis cég Computer Select CD-ROM adatbázisában hasonlóan rövid időtartam - egy év - anyaga volt, jó okkal. A PC Magazine Plus, egy másik CD-ROM termék hasonló elveket követ, s minden új kiadásában az utolsó 12 hónap számait tartalmazza, levágva a 13. hónap anyagát. Ezt a szokatlan feltártság-típus gördülő feltártság néven is ismert. A számítógépes szakirodalom avul el a legrövidebb idő alatt, különösen azok a cikkek, amelyek új számítógépes hardverről vagy szoftverről számolnak be vagy azt értékelik. A tegnapi hírek már történelemnek számítanak a számítógépes technikában.
Ez nem érvényes ugyanúgy a számítógép-tudományi kutatásokról beszámoló cikkekre, bár figyelemre méltó, hogy az Institute for Scientific Information (ISI) Journal Citation Reportsában a természettudományi részhalmazon belül a számítógép-tudományi folyóiratoknak van a legrövidebb felezési ideje. A hivatkozási felezési idő azt jelenti, hogy a megjelenés idejétől számítva visszamenőleg hány év alatt jön össze a hivatkozások 50%-a egy adott folyóiratban. Ezek nagyon hasznos adatok annak megítéléséhez, hogy egy adatbázis retrospektivitása mennyire felel meg egy adott diszciplínának.
Bár az irodalomkeresésben a retrospektivitás igénye egyéni preferenciák szerint változik, s ugyanazon egyén esetében is különböző témákhoz kapcsolódóan, az avulás egy adott szakterületen jó mérőszám, amihez képest meg lehet ítélni az adatbázisban feldolgozott időtartamot (az adatbázis retrospektivitását).
A könyvtár- és információtudomány területén a hivatkozási felezési időt az ISI által figyelt 56 folyóirat közül 21-re számolják ki, csak azokra, amelyek 100 vagy több hivatkozást kaptak. A hivatkozási felezési idő több mint 10 év volt két folyóirat esetében, 1,2 és 8,8 év között volt a többinél. (Az ISI nem számolja ki a pontos hivatkozási felezési időt azokban az esetekben, amikor az több mint 10 év.) A felezési időnek ezek az adatai megfelelő perspektívába állítják a könyvtár- és információtudományi adatbázisok és a jelentős könyvtár- és információtudományi anyagot tartalmazó adatbázisok retrospektív feltártságát, amit a 4.16. ábra mutat. Ez azt sugallja, hogy a 15-20 éves időtartam több mint megfelelő lenne a legtöbb keresés esetén. Ha a keresőt a széles körben használt szakmai folyóiratok érdeklik a könyvtár- és információtudomány területén a tudományos folyóiratok helyett, még rövidebb időtartam is elég lehet. Ez megfelelő megvilágításba helyezi az adatbázisok retrospektív feltártságának fontosságát.

4.15. ábra: Könyvtár- és információtudományi folyóiratok hivatkozási felezési ideje.

4.16. ábra: A könyvtár- és információtudományhoz kapcsolódó adatbázisok retrospektivitása
Hasonló módon az ISI által figyelt pszichiátriai folyóiratok hivatkozási felezési ideje is jól jelzi a retrospektivitás értékét PsycINFO és a Mental Health Abstracts adatbázisok esetében. Bár az utóbbi a pszichológia szélesebb diszciplínájával foglalkozik, a Mental Health Abstracts fókusza a pszichiátria (az adatbázis reklámanyaga szerint), így az ISI adatbázis pszichiátriai részhalmazának 80 folyóirata megfelelőbb alap lehet az összehasonlításhoz. Az ISI a "10 years" (10 év) jelzést használja azokra a folyóiratokra, amelyeknek hivatkozási felezési ideje több mint 10 év. Levonva ezeket a 63 olyan folyóiratból álló részhalmazból, amelyeknek van hivatkozási felezési ideje (a folyóiratok teljes pszichiátriai részhalmazából), az érték 2,6 év és 9,6 év között van (4.17. ábra). A hivatkozási felezési idő nem feltétlenül tökéletes mérőszám. Azoknak, akik tudományos folyóiratokban publikálnak, idézniük kell másokat. Sokan csinálják ezt anélkül, hogy akár manuális keresést végeznének vagy elolvasnák a hivatkozott cikkeket, egyedül az adatbázisok referátumaira támaszkodnak. Ennek aztán hatása van a hivatkozási felezési időre.

4.17. ábra: Pszichiátriai folyóiratok hivatkozási felezési ideje.
Az ember azt gondolhatná, az, hogy a PsycINFO adatbázisban feldolgozott anyag 1966-ig megy vissza, több mint elegendő a hivatkozási felezési idő fényében. Érdekes és szokatlan fejlemény az, hogy az Amerikai Pszichológiai Társaság (American Psychological Association) jelentős számú rekorddal, 300000 dokumentum anyagával egészítette ki az adatbázist, gondosan és szisztematikusan kiválasztott 1966 előtti publikációkkal.
A spektrum másik végén találjuk a humán tudományok diszciplínáit, ahol az elmúlt századokban megjelent könyveket, értekezéseket és cikkeket gyakran használják a mai kutatók. Sok társadalomtudós számára a negyedszázados anyag kurrensnek számít. Ebből a szempontból az ISI Arts and Humanities Search (20 év) és a Wilson cég Humanities Abstracts (16 év) retrospektivitásának különbsége jelentős lehet.
Az adatbázis szintjén vizsgált időtartamon túl figyelni kell egy szakterület magfolyóiratai és egyéb fontos folyóiratai feltártságának egyedi különbségeire is. Ezek közé tartozik a feltárás késői kezdése, korai abbahagyása, az egyenetlen feltártság és a hézagok a feltártságban. Ezekhez a szimptómákhoz kapcsolódik a feltártság sekélysége és lassúsága, de ezeket a feltártság mélységével kapcsolatos részben tárgyaljuk, a frissesség és az aktualizálás mintáit pedig később ebben a fejezetben. Az időszak feltártsága problémáit az ISA adatbázis alapján illusztráljuk, amely a sok folyóirat különleges egyedi sajátosságainak a legszélesebb választékát kínálja.
Egy adatbázis induló dátuma általában a legkorábbi évet jelzi, amelyből a publikációk egy részét felveszi a szolgáltatás, és semmiképp sugallhatja azt, hogy akkortól minden forrást feldolgoznak. Ez nyilvánvaló olyan esetekben, amikor egy cím később kezdett megjelenni az adatbázis induló időszakánál. Például az Internet Reference Services című folyóirat lehetséges feltártságának legkorábbi dátuma 1997 - amikor a lap elindult - függetlenül attól, hogy mi az adatbázis indulási ideje. Sok adatbázis azonban nem kezd el egy folyóiratot azonnal feldolgozni. Amikor egy folyóiratot kiválasztanak, lehetséges, hogy csak attól az évtől kezdve tárják fel, vagy retrospektív feltárással az indulás évétől. Ez az utóbbi jobb megközelítés ésszerű határok között, feltételezve, hogy a szakterület igazi magfolyóiratai közül semmi sem hiányzik az adatbázisból.
A címek késői felvétele a legkönnyebben úgy állapítható meg, ha összehasonlítunk versengő adatbázisokat, ahogy azt a 4.18. ábra illusztrálja. Egy adatbázis által feltárt időszak jellegzetességeinek megállapításához a leghatékonyabb módszer az, hogy megjelenítjük a kiadási év indexét. A folyóiratok szintjén a feltárt időszak gyorsan megállapítható a DIALOG RANK parancsával. Ez kibontja egy, a felhasználó által meghatározott mezőnek az értékeit, mint például a kiadási évet ebben az esetben, s rangsorolja őket az előfordulás értékei szerint vagy betűrendben. A rangsorolható eredményhalmazok méretének van határa. Jelenleg ez 10000 rekord.
Miután kiválasztottuk a legfontosabb folyóiratokat és mindegyikükre vonatkozóan megalkottuk a halmazt, ezeket rangsoroltatni kell, megjelenítve a rekordok számát minden egyes évre kronológiai sorrendben (4.19. ábra). Ami szembetűnő az ISA adatbázisban a kiváló brit könyvtár-gépesítési folyóirat, a Program esetében, az nem a feltárt időszak, hanem a feltártság mértéke, vagy inkább a mélység hiánya. Nehéz eldönteni, vajon hézagnak tekintsük-e az évek kihagyását (mint 1972, 1975-1976, 1978-1979, s majdnem egy évtized 1988 és 1996 között), a feltárás korai abbahagyásának, időleges felfüggesztésének vagy csak egy szánalmas feltáratlanságnak. Az 1977-ből származó egyetlen tétel még életjelnek sem elég.

Az adatbázis indulási ideje / Az RQ-ból származó rekordok / Késői indulás években kifejezve
4.18. ábra: Magfolyóiratok későn kezdett feltárása
Egyes adatfájl előállítók olyan folyóiratlistát szolgáltatnak, amely világosan jelzi, melyik évtől tárnak fel egy adott folyóiratot s melyik évben hagyták abba a feltárást. (A feltárás abbahagyása sok okkal igazolható. A természetes az, amikor egy folyóirat megszűnik vagy megváltoztatja címét; azaz a feltártság az alatt a cím alatt szűnik meg.) Az EBSCO, a Bell & Howell és az H. W. Wilson cégek a feltárás kezdő és befejező évét is jelzik, a folyóiratok listáját elérhetővé teszik a weben.
Egyes folyóiratlisták mintái elérhetőek a http://www2.hawaii.edu/~jacso/extra/savvy/journalbase/journalbase.html címen.
Egyesek lehetővé teszik a felhasználó számára, hogy a folyóiratlista outputját személyre szabja. A Bell & Howell például felkínálja a választást, hogy a következő mezők közül melyek szerepeljenek: Cím, a folyóirat kódja, ISSN, a referálás kezdetének dátuma, a teljes szöveg közlése kezdetének dátuma és a képi formában való közlés dátuma. A LISA publikált egy folyóiratlistát a weben 2000-ben, de ez már akkor is elavult volt. Nem tartalmazza azokat a folyóiratokat, amelyeknek a címe megváltozott 1999-ben, mint például a Database EContentre vagy a Library Software Review Library Computingra. Csak a régi címek alatt sorolják fel őket (Database és Library Software Review).
A LISA folyóiratlistájának tartalma a lehető legegyszerűbb: csupán a folyóirat címe szerepel. Az ISA még kevésbé informatív a folyóiratairól. Az új szerkesztői gárda azonnal leállította a magfolyóiratok listájának közreadását. Kétségtelen, hogy kellemetlen ténynek bizonyult, hogy a korábbi fájlkészítők hanyagul kezelték az időszaki kiadványokat azzal, hogy kihagyták magfolyóiratok teljes számait, köteteit vagy több kötetét, amelyeket pedig teljes egészükben indexelniük kellett volna (Jacsó 1997e). Ehelyett egy szerkesztőségi cikk felsorolt új folyóiratokat, amelyeket a jövőben fel akartak tárni.
(http://www2.hawaii.edu/~jacso/extra/savvy/journalbase/journalbase.html)

4.19. ábra: Egy folyóiratból vett tételek rangsorolása a kiadási év szerint, időrendben.
A felsorolt címek némelyike megszűnt jóval a bejelentés előtt: másokat nem tártak fel a következő évben, míg továbbiak csupán egy vagy két rekordot produkáltak 1998-ban, 1999-ben és 2000-ben, beleértve két olyat, amelyeket a szerkesztők a használóknak különösen a figyelmébe ajánlottak (4.20. ábra)
Az adatbázisok kiadói (szemben a fájlok előállítóival) általában nem teszik elérhetővé az egyes időszakok feltártságával kapcsolatos információkat, bár ezt könnyű lenne megtenni az adatbázis online vagy CD-ROM változatának súgójában.
A fájlok előállítói által szolgáltatott folyóiratlistákról a feltárás kezdetét nem lehet készpénznek venni. Egyes fájl előállítók olyan folyóiratokat mondanak feltártnak, amelyeket csupán az adatbázis néhány kezdeti évében vettek fel. A Magazine Article Summaries (MAS), az EBSCO első indexelő és referáló adatbázisa azt állította, hogy a legtöbb címet 1984-től feltárja. Valójában csak néhány rekorddal hintették meg az adatbázist (még a nagyközönségnek szóló, kétségtelen magfolyóiratok esetében is) 1984-től (és gyakran későbbtől) a folyóiratok számaiból (4.21a ábra).

4.20. ábra: Új folyóiratok, amelyek feltárását ígérte az ISA és tényleges feltártságuk
Egy gyors pillantás alapján is nyilvánvaló, hogy éles ellentétben van ezzel az H. W. Wilson cég adatbázisaiban a folyóiratok jellegzetesen alapos és kiegyensúlyozott feltártsága, ahogy azt a 4.21.b ábra mutatja. (Egy hirtelen hullámzást a feltártságban (a feltárt tételek számában) megindokolhatja az, ha egy folyóirat megjelenési gyakorisága növekszik vagy más okból nő az egy adott évben publikált cikkek száma. Ez volt a helyzet, amikor a CD-ROM Professional havi megjelenésű magazinná vált, míg azelőtt csak évi hat száma jelent meg.

4.21a. ábra: Az adatbázis meghintése néhány tétellel fontos forrásokból a MAS adatbázisban.

4.21b. ábra: Fontos források jól kiegyensúlyozott feltártsága a Readers' Guide Abstracts adatbázisban.
Mélység
Az adatbázisban szereplő folyóiratok feltártsága mélységének vizsgálata és megértése alapvető akkor, amikor az adatbázisnak a minőségét értékeljük. Pusztán az, hogy egyes folyóiratok jelen vannak az adatbázisban, nem garantálja, hogy megfelelő mértékben fel is tárják azokat. Az 1960-as években és az 1970-es évek elején a folyóiratok feltártságára vonatkozó vizsgálatok gyakran korlátozódtak annak meghatározására, hogy folyóiratok csoportjai szerepelnek-e egy vagy több nyomtatott indexelő és referáló forrásban, s milyen átfedés van köztük a folyóiratok szintjén. Ezek a vizsgálatok általában az indexelő és referáló források kumulált indexein alapultak, de még így is fárasztó, unalmas munkát jelentettek. Gilchrist (1966), Goldstein (1973) és Edwards (1976) alapos vizsgálatai a folyóiratcímek szintjén való összehasonlításra korlátozódtak, s nem tárgyalták a folyóiratok feltártságának mélységét. Így is előkészítették az utat a későbbi vizsgálatokhoz, amelyek összehasonlították a kiválasztott folyóiratok feltártságának mélységét az adatbázisokban.
Fontos tudni, hogy nem csak az alkalmi használók nem veszik észre, hogy fontos folyóiratok milyen sok cikke hiányzik egy adatbázisból, hanem kutatók sem, akik bibliometriai és tudománymetriai kutatásokat végeznek. Ezek a kutatások a kiadás mintáit és a hivatkozási szokásokat vizsgálják, hogy rangsorolják a szerzőket, intézményeket, folyóiratokat, sőt országokat is az adatbázisokban végzett keresések alapján. Kutatási frontokat és trendeket vizsgálnak olyan diszciplínákban, ahol a folyóirat-publikációk a domináns források a termékenység jelzéséhez. A publikációs produktivitás az alapvető szempont előléptetések, támogatások és meghatározott állások esetében. Súlyosan torzíthatják a bibliometriai és tudománymetriai vizsgálatok eredményeit a hézagok és a feltártság jelentős hullámzása, valamint a folyóiratok anyagának sekély, következetlen, lassú feltárása vagy a feltárás idő előtt való abbahagyása, s félrevezethetik azokat a használókat, akik azt gondolják, hogy amit találtak egy adatbázisban, az minden, amit a témáról az adatbázisban feltártnak mondott nagy presztízsű folyóiratokban írtak.
A hozzáértő használók azonban tudják, hogy két vagy három adatbázisban kell keresniük ahhoz, hogy megfelelően részletes (alapos) keresési eredményekhez jussanak. Azonban még tapasztalt használók is áldozatául eshetnek az adatbázisok feltártságáról szóló valótlan állításoknak, a klisészerűen megírt reklámanyagokban szereplő, mindenre kiterjedő feltárásról szóló ígéreteknek. Ahogy azt a 3. fejezetben láttuk a tárgyi feltártsággal kapcsolatban, a legabszurdabb PR állítások könnyen ellenőrizhetőek a címekben szereplő szavak alapján végzett kereséssel több adatbázisban. A folyóiratok feltártságának mélységét, kimerítő voltát nehezebb igazolni.
A folyóiratcímek rövidítésének, központozásának és helyesírási változatainak nagy sokasága egyes adatbázisokon belül és különböző adatbázisok között defenzív keresési stratégiákat követel meg, amely megjósolja, felkutatja a lehetséges variációkat, s igazodik hozzájuk. Amikor a folyóiratcímek mezőjét csak mondatonként és nem szavanként indexelik (mint a legtöbb DIALOG adatbázisban), a keresőkérdés megalkotása elég nehéz feladat. Ha a folyóiratcím mezőt szavanként és kifejezésként is indexelik, a keresőkérdés sokkal rugalmasabban megalkotható, mint például a legtöbb adatbázis Ovid és OCLC változataiban.
A nyomtatott útmutatók és a folyóiratok listái minden egyes folyóiratra vonatkozóan tartalmazhatják az első és az utolsó feldolgozott évet. Ezek hasznosak lehetnek az ezeket a listákat vizsgáló használók orientálására, de azt nem garantálják, hogy a jelzett években valóban alaposan feltárták ezeket a lapokat. Ahogy az előző fejezetben láthattuk, az újonnan feldolgozott folyóiratok büszke bejelentése sem garancia. Az is elég gyakori, hogy a jelzett időszakból az első évben a folyóirat feltártsága elég sekély. Ez igaz lehet az egész adatbázisra, ahogy azt az a példa bizonyítja, amelyben hét folyóirat első néhány évének a Readers' Guide Abstractsben és a Magazine Article Summariesben való feltártságát hasonlítottuk össze. A feltártság ábrázolása 4.21a és a 4.21b ábrákon magáért beszél.
A folyóiratoknak magfolyóiratként való besorolását nem lehet készpénznek venni minden adatbázisban. Az ilyen meghatározás a legkimerítőbben (általában borítótól borítóig) feltárt folyóiratokra érvényes. Meghatározott dokumentumtípusok kihagyása egy magfolyóirat egy számából (mint a nekrológok és a hírek) elfogadható lehet (különösen, ha ezt egyértelművé teszik a dokumentációban vagy a súgóban, s ha ezt a szabályt következetesen alkalmazzák). A nagy cikkek kihagyása azonban nem fogadható el. Állítólagos magfolyóiratok teljes számainak vagy köteteinek kihagyása egyenlő azzal, amit más szakmákban műhibának nevezünk. A könyvtár- és információtudományi anyagot feltáró adatbázisok között csak az ISA és az INSPEC az, amely egyes folyóiratokat magfolyóiratokként határoz meg, s az ISA abbahagyta ezt a gyakorlatot, ahogy azt a korábbiakban már megtárgyaltuk. Meghatározásuk szerint az ISI adatbázisokban minden folyóirat magfolyóirat külön jelzés nélkül, mivel az ISI adatbázisokban minden folyóiratot borítótól borítóig feldolgozottnak mondanak.
A magfolyóiratokhoz való hozzájutás nehézségeire utaló kifogások (Allcock 1997) nem tűnnek jogosnak, figyelembe véve, hogy az ISA összes magfolyóirata az USA-ból, Nagy-Britanniából és Kanadából származik. Ugyanez vonatkozik a folyóiratok magas árára is. Ez a dolog velejárója, s nem igazolja teljes kötetek kihagyását (Jacsó 1997e). Az ilyen állítások nem kelthetnek szimpátiát olyan használókban, akik magas árakat fizetnek az adatbázisokért és akik tudják, hogy a legtöbb állítólagos magfolyóirat éves előfizetési ára egy könyvtár- és információtudományi adatbázisban 100 dollár alatt van.
Egyes folyóiratok egyetlen adatbázisban való feltártságán túltekintve jobb perspektívát nyerhetünk, ha van valamilyen szint, amihez a feltártság mélységét viszonyíthatjuk.
Az adatbázisban feltárt anyag időbelisége nem választható el a feltárás mélységétől. A mélység nem könnyen meghatározható, mert mozgó célpont. A feltárás mélysége - azaz a rekordok mennyisége egy folyóiratból az adatbázisban való feltártsága idején - évről évre változik, függetlenül a folyóiratban évente megjelenő cikkek mennyiségének lehetséges változásaitól. Ezt mutatta a korábbi, 4.19. ábra, a Program című, nagyhírű könyvtár-automatizálással foglalkozó brit folyóirat szánalmas feltártsági mintája az ISA adatbázisban.
Rendkívül egyenetlen, hullámvasútszerű feltárás nagyon lehangoló olyan folyóiratok esetében, amelyek a szakterületük élvonalbeli kiadványai, és elfogadhatatlan valódi magfolyóiratok esetében. A Library Quarterly feltétlenül megérdemelné, hogy egy kötetének minden cikkét felvegyék egy adatbázisba, de az ISA esetében szemmel láthatóan nem ez a helyzet (4.22. ábra). Ugyanez érvényes egy másik nagyra tartott folyóiratra, a Library Trendsre. Anélkül, hogy megnéznénk feltártságát más adatbázisokban, teljesen nyilvánvaló, hogy a kiszámíthatatlan feltártságnak semmi köze ahhoz, hogy épp mennyi cikk jelent meg ebben a két folyóiratban.

4.22. ábra: A Library Quarterly hullámvasútszerű feltártsága az ISA-ban.
Amikor hasonló minta érvényesül az ISA-ban olyan magfolyóiratok esetében, mint a Government Information Quarterly, Journal of Documentation, RQ (most Reference & User Services Quarterly) vagy az Information Technology and Libraries (4.23. ábra), akkor az ember nehezen találja elhihetőnek, hogy "a magfolyóiratokat a maguk teljességében feldolgozzuk", ahogy azt az ISA Használói útmutatója állítja.

4.23. ábra: Az Information Technology and Libraries hullámvasútszerű feltártsága az ISA-ban.
A hullámvasút lefelé menő részének különleges esete az a hézag, ami akkor történik, amikor egyetlen rekord sincs egy egész kötetből vagy több kötetből. Bár az ember együtt érezhet az adatbázis szerkesztőjének azzal a problémájával, amit az ISA korábbi adatbázis szerkesztője osztott meg velünk (Allcock, 1997), hogy alkalomszerűen hiányzik egy vagy két lapszám, az ISA adatbázis esetében ez visszatérő probléma, amire nincs példa egyetlen más adatbázisnál sem. Ez nagy probléma nagypresztízsű folyóiratok esetében még akkor is, ha nem tekinti őket magfolyóiratnak az adatfájl készítője, ahogy ez a Program című folyóirat esetében (4.24. ábra) előfordult, s még nagyobb probléma az adatbázis magfolyóiratai esetében, mint a Scientometrics (4.25. ábra).

4.24. ábra: Hézagok a nagy presztízsű Program feltártságában az ISA-ban.
4.25. ábra: Hézagok a Scientometrics című magfolyóirat feltártságában az ISA-ban.
A hézag (a feldolgozás időleges felfüggesztése) a feldolgozás korai megszüntetésévé változhat egy fontos folyóirat esetében. Néha nehéz megállapítani, hogy egy folyóirat feltárása milyen állapotban van. A feltárás néhány éves teljes felfüggesztése után, néhány, a klinikai halál állapotában levő cím (a fájl készítőjének perspektívájából) némi életjelt mutat. Ez volt a helyzet az RQ, az egyik legmagasabban rangsorolt könyvtári folyóirat esetében, amely az ISA nyomtatott kiadásában a magfolyóiratok listáján maradt 1994-ben és 1995-ben, annak ellenére, hogy ezekből az évekből egyetlen rekord sem került be az adatbázisba az RQ-ból. 1996-ban újra felbukkan az ISA-ban, de csupán négy rekorddal. Ez elég sajátos kezelése egy magfolyóiratnak. Egy csavar a kiváló folyóirat feltártságában az volt, hogy 1997 közepén a korábbi cím, RQ alatt valóban megszüntették kiadását. 1998 végéig új címe, Reference & User Services Quarterly alatt sem választották ki feldolgozásra az ISA-ban.
Nehéz megérteni, hogy egy fájl előállítója miért hagyja abba egy olyan folyóirat feldolgozását, amelyet kulcsfontosságúnak tekintenek szakterületén. Ez történt a LISA adatbázissal, amikor leállította az Online magazin feldolgozását. 2000 végén még mindig nem voltak rekordok a folyóirat 1999-es és 2000-es számaiból (4.26. ábra). Nem lehet eldönteni, hogy ez feltárás szüneteltetése vagy megszüntetése. Bármelyikről van szó, baklövés. Ugyanez történhet az EContenttel is a LISA-ban. Míg az 1999-es számokból 36 rekord került be az adatbázisba, a 2000-esekből egyetlen sem. Miután ezeket az eredményeket bemutatta egy konferencián, a szerzőnek azt a választ kapta, hogy a LISA erőfeszítéseket tesz a hiányok pótlására, s folytatják ennek a két fontos folyóiratnak a feldolgozását. Valóban, mikorra ez a könyv nyomdába ment, a LISA 2001. június 28-i aktualizálása során kiegészítették ezekkel a hiányzó rekordokkal. Jobb későn, mint soha.

4.26. ábra: Az Online című folyóirat feldolgozásának felfüggesztése vagy megszüntetése a LISA adatbázisban.
Az ISA adatbázis új előállítója megpróbálja befoltozni azokat hézagokat, amelyekkel először egy publikálatlan dokumentumban szembesítette az ISA igazgatótanácsát ennek a könyvnek a szerzője, később egy cikkben publikálta erre vonatkozó eredményeit a Library and Information Science Research című folyóiratban (Jacsó 1998a). Ezekre a visszamenőleges teljessé tevő próbálkozásokra nagyon nagy szükség volt, de hatással volt fontos folyóiratok új számainak feldolgozására is, ahogy azt ennek a fejezetnek a frissességre vonatkozó részében megtárgyaltuk. A hiányok pótlását 1990-től kezdve tervezték (ésszerű cél), de számos olyan cím esetén nem érték el, amelyek alapvető fontosságúak az adatbázis szakterületén.
A címjegyzék adatbázisokban való retrospektív feltárás összetettebb kérdés. Bizonyos címjegyzékekben, mint például cégek címjegyzékeiben és ki kicsoda típusú adatbázisokban a retrospektív feltárás nem olyan fontos, mert a használókat leginkább a friss cégadatok érdeklik, mint például a jelenlegi név, cím, e-mail cím és faxszám, mivel általában egy rekordot készítenek minden kiadás számára és a korábbi kiadások rekordjait is megtartják. Ugyanez érvényes filmes és zenei címjegyzékekre is. Ilyen esetekben fontos tudni, időben mennyire megy vissza az adatbázis. A Kongresszusi Könyvtár REMARC adatbázisa az egyik olyan könyvkatalógus, amely a leginkább retrospektív, és különösen fontos olyan kutatók számára, akik fel akarnak kutatni egy, a 15. században megjelent könyvet. Ezt nem lehet elvégezni a Books in Print, British Books in Print, Amazon.com, Barnes & Noble vagy akár a Books Out of Print adatbázisban.
A bibliográfiai és a teljes szövegű adatbázisokhoz hasonlóan a címjegyzékek esetében sem szabad elfogadni azt, amit az adatbázis kezdő évének mondanak. Gyakran csak néhány rekord van ebből az időszakból. Másrészt azonban mind a bibliográfiai, mind a címjegyzék adatbázisok gyakran sokkal jobban visszamennek időben, jelentős számú rekorddal az előttről, mint ami az adatbázis címkéjén szerepel vagy amit a reklámanyagok állítanak. Az ISA például elég sok 1966 előtti cikket tartalmaz, pedig azt határozták meg indulási évként. Az Ovid honlapján 1979-et jelöli meg az AGRICOLA indulási éveként, de a kiadási év indexe azt mutatja, hogy jelentős anyag található benne az 1970-es évek közepéről (4.27. ábra).

4.27. ábra: Az AGRICOLA korábban kezdte a jelentős mértékű feltárást, mint ahogy azt állították.
Ha ábrázoljuk az egyes időszakokból feltárt anyagot, rendkívül lényeges különbségeket mutathatunk ki az adatbázisok között. Míg a PsycINFO jelentős növekedést mutat a feltárt anyagban az évek során, ami tökéletes összhangban van a szakterület publikációinak mennyiségi növekedésével, addig a Mental Health Abstracts példátlan csökkenést mutat azóta, hogy 1983-ban az IFI/Plenum átvette (4.28. ábra). Az éves növekedés mennyisége nagyságrendekkel csökkent. A két adatbázis, amely fej-fej mellett haladt az 1980-as évek elején, azóta ellentétes irányba halad. Zuhanórepülése, a feltárt források, a folyóiratbázis és a feltárás mélységének drámai csökkenése miatt, ahogy azt az 5. fejezetben megtárgyaljuk, az MHA-t nagyon kis mértékben tudják hasznosítani a pszichiátriát és pszichológiát hallgató egyetemisták és a gyakorló szakemberek.
Az MHA hasonló problémákat mutat a feltárt folyóiratok szempontjából, mint amit az előzőkben az ISA-ról elmondtunk. Bár sohasem különböztette meg magfolyóiratokat a rendszeresen és alkalomszerűen feltárt folyóiratoktól, sok alapvető folyóirat feltárásának megszüntetése olyan területekről, amelyeken az MHA különösen hasznosnak tekinthető, mint a pszichofarmakológia és a pszichiátriai kezelés, aláásta ezt az adatbázist (bár néhány előfizető egyetem nem vette észre és továbbra is előfizet az MHA adatbázisra).

4.28. ábra: A PsycINFO és az MHA adatbázisban feldolgozott anyag mennyisége évenkénti bontásban
Az adatbázisok által feldolgozott időszak meghatározása könnyű. A legtöbb rendszerben a kiadási év indexe megjeleníthető és letölthető egy fájlba, amelyből egy táblázat generálható. Ha ez az opció nem elérhető, a kiadási évre vonatkozó kereséssorozatot lehet elvégezni, az eredményként megkapott keresési eredmények elmenthetők egy fájlba, s onnan egy táblázatba importálhatók. Bár az adatgyűjtés gyors és könnyű, mindig gondos megközelítést igényel. Ahogyan azt a 9., a rekord teljességéről szóló fejezetben megtárgyaljuk, sok adatbázisban építésük első néhány évében nem vették fel a rekordokba a kiadási évet. Másokban a kiadási év mező néhány egyéb adatot is tartalmaz. Ha ez jelentős mértékben történik így, akkor az torzíthatja az egy adatbázisban feltárt időszakról kapott képet.
A hibás adatokat nehéz észrevenni, kivéve azt, ha azok első pillantásra nyilvánvalóan hibásak. Mielőtt elhinnék, hogy az AGRICOLA-ban rekordok ezrei találhatók olyan dokumentumokról, amelyek Gutenberg születése előtt jelentek meg (4.29. ábra), gondoljanak arra, hogy ezek sajtóhibák (például 1078 1978 helyett) vagy más hibás számok, amelyeket begépeltek a kiadási év mezőjébe. Mielőtt valami összeesküvést sejtenénk a 2000-en túli kiadási évek esetében, jobb ha tudjuk, hogy valószínűleg ezek is sajtóhibák. Az ilyen kiadási év nem volt teljesen lehetetlen 1999-ben egyes adatbázisokban, de csak olyanokban, mint az EVENTSLINE, amelyben 2005-ig vannak rekordok tervezett eseményekre, vagy a Books in Printben, amelyben van egy részhalmaz, amely a jövőben megjelenő címekre vonatkozó rekordokat tartalmazza.

4.29. ábra: Lehetetlen kiadási évek az AGRICOLA adatbázisban.
Hasonló módon abszurdak a PY=200 értékek az Information Science Abstracts adatbázisban, ezeket az első 2000-es aktualizálás idején bekerült rekordok kapták. Azon túl, hogy ez elég rossz kezdés volt az új évezredben (ha önök azt fogadják el, hogy az 2000-ben kezdődött), ez megfosztotta tőlük azokat a használókat, akik keresésüket a kurrens évre szűkítették, hogy potenciálisan releváns és friss rekordokhoz jussanak. Bár ez a hibás kiadási év csak 71 rekordban jelenik meg, ezek 100%-át jelentik azoknak a tételeknek, amelyeket a 2000-es év első aktualizálásakor folyóiratok 2000-es számaiból adtak hozzá az adatbázishoz. Ironikus látni a tévedést egy olyan cikk rekordjában, amely a Y2K bug túlélését említi - kétségkívül egy kicsit túl korán (4.30. ábra). Az év folyamán később az ISA korrigálta ezeknek a rekordoknak a kiadási évét.

4.30. ábra: A Y2K bug az ISA egyik rekordjában
Amikor egy fájl előállítását egy új cég veszi át, mindig érdemes újra meglátogatni és -értékelni egy adatbázis minőségét, benne a feltártság mélységét. Ez történt 1998-ban, amikor az Information Today megszerezte az ISA adatbázist és alkalmazta a korábbi technikai tanácsadót. Bár az új producer megszüntette a magfolyóiratok listáját, az adatbázis szakterületi feltártságával kapcsolatos, revideált megállapítások (4.31. ábra) tartalmaznak néhány kiindulópontot ahhoz, hogy ellenőrizni lehessen a feltártság mélységéhez kapcsolódó, nagyon szükséges változásokat azokban a témákban, amelyeket az adatbázis elsődleges területeinek tekintenek. A 30 hónap, ami eltelt az ISA átvételétől ennek a könyvnek a befejezéséig, elég időt adott ahhoz, hogy lássuk, vajon a pozitív változások megvalósultak-e.

4.31. ábra: Az ISA adatbázis tárgyi feltártságára vonatkozó, revideált állítás.
Sajnos a feltártság mélységének problémái az adatbázis (állításuk szerint) elsődleges területein (ahogyan a frissesség hiányának problémái is) az ISA adatbázis új vezetősége idején is megmaradtak A kiadási évre vonatkozó gyors keresés is arról árulkodik, hogy az adatbázisba kerülő rekordok száma drasztikusan csökkent az elmúlt három évben az új vezetőség alatt (4.32. ábra).
A tényleges számok ellentmondanak az 1998 októberi szerkesztőségi cikk ígéretes megállapításainak, amely szerint, hogy "az ISA következő néhány száma több cikket fog tartalmazni, mint általában (szokott)" Éppen az ellenkezője történt. Ez a trend nagyon valószínűtlenné teszi, hogy a feltártság mélysége az adatbázis elsődlegesnek minősített szakterületein fejlődni fog.
A feldolgozott folyóiratok száma nem változott jelentős mértékben 2000-ig (4.34. ábra), ami azt sejteti, hogy ha sokkal kevesebb rekord került be az adatbázisba a legújabb 30 hónapban, ez csak úgy lehetséges, ha a folyóiratok (és a témák) feldolgozottsága még sekélyebb volt. 1999 óta konferencia-kiadványok címeit a folyóiratcím mezőben szerepeltetik, és a konferencia előadások dokumentumtípusként az "article" (cikk) megjelölést kapták (egy újabb dokumentumtípus, azután, hogy a konferencia előadások besorolása a "monographic" és a "monographic chapter" dokumentumtípusok között váltakozott). Ez növeli mind a feldolgozott "folyóiratok", mind a feldolgozott "cikkek" számát ebben a két évben, így a kép valamivel rosszabb, mint amilyennek tűnik.

4.32. ábra: Az ISA adatbázishoz adott rekordok számának gyors csökkenése a legutóbbi években.
Szerkesztőségi cikk. 1988 október
A frissesség fontos kérdés egy referáló adatbázis kiadója számára, mi sem vagyunk kivételek ez alól itt az Information Today-nél. Örömmel közöljük, hogy az Information Science Abstractsnek (ISA) nincs lemaradása. Mihelyt a folyóiratok megérkeznek a kiadóktól, a releváns cikkeket kiválasztjuk belőlük, s azután elküldjük őket elkötelezett és szorgalmas referálóinknak. A referátumok általában 10 nap múlva (vagy még hamarabb) visszaérkeznek hozzánk, s azután megjelennek az ISA következő számában.
A fenti állítások fényében az ISA olvasói csodálkozhatnak, miért tartalmaz ez a szám néhány olyan referátumot, amelyek egészen 1990-ig mennek vissza. Ez része az ISA minőségfejlesztő programjának, amit egy korábbi szerkesztőségi cikkben már megemlítettünk. A legújabb technika felhasználásával részletesen, mezőről mezőre áttekintettük az ISA régi anyagot tartalmazó fájlját abból a célból, hogy kijavítunk sok olyan hibát, amely a 30 éves létezés során becsúszott. Ez a folyamat több hiányt tárt fel sok folyóirat feltártságában. Várakozásaink szerint ezekhez a cikkekhez referátumokat kapcsolunk az ISA későbbi számaiban, így az adatbázis feldolgozottsága a lehető legteljesebb lesz 1990-ig visszamenően. Mivel a frissességet is fenn fogjuk tartani, az ISA következő néhány száma több rekordot fog tartalmazni, mint általában.
Miután a minőségfejlesztési programot befejeztük, figyelmünket várhatólag az ISA-ban feldolgozott folyóiratok számának jelentős mértékű növelése felé fogjuk fordítani. Ezért nyomatékosan kérjük javaslataikat az új címekre.

4.33. ábra: Néhány ígéretes állítás egy korai ISA szerkesztőségi cikkből.
Az adatbázis szerkesztői által írt, a DIALOG által publikált esszé (http://library.Dialog.com/products/f202.html) fényében, amely azt állította, hogy nincs semmi lemaradása az adatbázisnak, a 2000 szeptemberi tény, hogy csak 114 primer forrás volt (beszámítva a konferenciaköteteket), azt sugallja, hogy nem csak a rekordok száma csökkent, hanem a 2000-ben feldolgozott források száma is (4.34. ábra). (Mivel az adatbázis jelenleg nem érhető el a DIALOG-nál, ezért természetesen ez a dokumentum sem található a jelzett címen.
Ugyanaz a 4.33. ábrában bemutatott szerkesztőségi cikk felvázolta tervüket "az ISA által feldolgozott folyóiratok listájának jelentős mértékű növeléséről" is. Erre szemmel láthatóan nem került sor. Bár a 4.32. ábra számai valamennyire felduzzasztottak a folyóiratcímek következetlen, pontatlan, ebből következően különböző írásmódja miatt, ez egyformán érvényes a régi és az új vezetés időszakára, s nem torzítja el a képet.
A feltártság mélysége az egyes folyóiratok szintjén is gyatrább lett. A legutolsó három év mintái ugyanazt a sekély vagy hullámvasútszerű feltártságot és hézagokat mutatják, mint a melyik az adatbázis 1998 előtti szegmensét is jellemezte. Bár a magfolyóiratok listáját többé nem teszik közzé, a feltártság mélységének megállapítására mintaként kiválasztott folyóiratok reprezentálják a legfontosabb folyóiratokat, amelyek állítólag az ISA fókuszában vannak.
Például a MIS Quarterly (a teljesen kiírt, az ISA által szintén használt Management Information Systems Quarterly cím alatt is kerestük) meredeken csúszik lefelé (4.35. ábra), annak ellenére, hogy a könyvtár- és információtudományi kategóriában a Journal Citation Reports a legmagasabbra rangsorolta 1999-ben. Ugyanez a csökkenő trend igaz a Library Administration and Management című folyóiratra is, amely az ISA blusheetje (adatbázis-leírása) által elsődlegesnek jelzett szakterülethez kapcsolódik, s a Journal Citation Reports is magasan rangsorolta (4.36. ábra).

Kiadási év / A folyóiratok száma / A folyóiratokból származó rekordok száma / A rekordok teljes száma / Mélységtényező
4.34. ábra: Csökkenő mélységtényező 1995 és 2000 szeptembere között

4.35. ábra: Az MIS Quarterly feltártsága a lefelé vezető lejtőn van.

4.36. ábra: A Library Administration and Management csökkenő feltártsága az ISA-ban.
Az ISA adatbázis-leírásának a tárgyi feltártságot bemutató részénél első témaként sorolják fel a referálás és indexelés témáját, de az ennek szentelt NFAIS Newslettert 1999-ben teljes mértékben ignorálták, aztán 2000-ben újra visszavették, ahogy azt a 4.37. ábra mutatja.

4.37. ábra: Az NFAIS Newsletter teljes 1999-es anyaga feltáratlan az ISA-ban.
Fontos folyóiratok gyenge feltártságán túl van egy kérdés azokkal a folyóiratokkal kapcsolatban is, amelyeket egyáltalán nem vesznek fel, bár nyilvánvalóan a legjobb források közé tartoznak azon a szakterületen, amelyet az adatbázis feldolgozottnak mond. Ezeket a kérdéseket a folyóiratbázissal foglalkozó 5. fejezetben tárgyaljuk meg.
Frissesség
Az online adatbázisok egyik leggyakrabban említett előnye nyomtatott megfelelőikhez képest gyorsaságuk. Az adatbázisok frissessége arra utal, hogy a primer dokumentumok megjelenése után milyen gyorsan válik elérhetővé egy rekord CD-ROM vagy online adatbázisban. Ennek a mérőszámnak az értékeléséről nagy számban jelentek meg jelentések 1960-as évek óta a könyvtár- és információtudomány nyomtatott indexelő és referáló szolgáltatásairól Gilchrist (1966), Gilchrist és Presanis (1971), Dansey (1973), Edwards (1976) és Turtle és Robinson (1974) tanulmányaiban. Bottle és Efthimiadis (1984), Ernest, Lange és Herring (1988) és Jacsó (1992a) kiterjesztette az időbeli elmaradás (késés) vizsgálatát az elektronikus termékekre, s a könyvtár- és információtudományon túlra. Jacsó (1992a) különféle technikákat mutatott be az időbeli elmaradás széles skálán való mérésére. Ezeknek a technikáknak némelyikét használta Lawrence és Lenti (1995), amikor az International Aerospace Abstracts adatbázis frissességét tesztelték, összevetve néhány hozzá hasonló adatbázissal.
A hasonló anyagot feldolgozó adatbázisok összehasonlítása különösen informatív. Hightower és Schwarzwalder (1991) 24, az anyagtudományt feldolgozó adatbázis frissességét mérte. Az időbeli különbségek megdöbbentőek voltak. Míg néhány adatbázisnak sikerült a rekordok csaknem 67 százalékát felvenni az adatbázisba ugyanabban az évben, amikor az eredeti dokumentum megjelent, a Soviet Science & Technology adatbázisban egyetlen ilyen rekord sem volt. Ez megmagyarázhatja azt, hogy a "szputnyik nyomás" nélkül az NTIS is miért csak elszomorítón alacsony mértékben, 5%-ban tette a rekordokat elérhetővé abban az évben, amikor az eredeti dokumentum megjelent.
1998-ra ez az arány javult: a rekordok 18%-a jelent meg ugyanabban az évben. 1999-ben ez tovább nőtt, 24%-ra, de a mennyiség rovására. Amíg 1998-ban összesen 72143 rekordot adtak az adatbázishoz, addig 1999-ben csak 45430-at.
Soremark (1990) a MEDLINE-ba és az EMBASE-be is bekerült rekordokkal kapcsolatban azt tapasztalta, hogy az előbbiben átlagosan 2-4 hónapos volt a lemaradás. 1999-re a MEDLINE időszerűsége messze felülmúlta az EMBASE-ét - legalábbis a PubMed webhelyen, amely bevezette a PreMEDLINE rekordokat. Ezek a rekordok, amelyeket naponta adnak hozzá az adatbázishoz, alapvető bibliográfiai adatokat és referátumokat tartalmaznak, de MeSH deszkriptorokat nem. Amikor ezeket a rekordokat kiegészítik, kész MEDLINE rekordokká válnak. Erre az aktualizálásra naponta kerül sor a PubMed rendszerben. Figyelembe véve, hogy ez egy ingyenes adatbázis, nagy kincs azok számára, akik gyorsan tudomást akarnak szerezni a megjelenő publikációkról. A frissesség másik tesztje során, 1999. december 23-án medical keresőszó és 2000 mint megjelenési év (PY=2000) 186 rekordot adott az EMBASE-ben a DIALOG rendszerben és 443-at a PubMedben.
Jaguszewski és Kemp (1995) négy témafigyelő szolgáltatás frissességét hasonlította össze a kémia és a matematika területén. Úgy találták, hogy az Uncover volt a legfrissebb, a továbbiak sorrendje Inside Information, ContentsFirst és Current Contents on Diskette volt, bár a kémia területén a ContentsFirst frissebb volt az Inside Informationnél.
Azok a webes adatbázisok, amelyeket közvetlenül a fájlok előállítói szolgáltatnak, drámai módon növelik az adatbázisok naprakészségét, mivel a közvetítő, az adatbázis kiadója kiiktatódik. A mostani korai szakaszban a tartalomszolgáltató által közvetlenül a weben való megjelentetés az adatbázisok közreadásának egy újabb csatornája a már létezők mellett. Hosszútávon ez a trend fenyegetheti az online szolgáltatásokat, amelyek mások tartalmát publikálják. Mivel a weben keresztül mindenki elérhető, harmadik fél tartalmát közvetítő online kiadóknak keményen kell dolgozniuk, hogy igazolják a plusz költségeket és a közvetítésből adódó elkerülhetetlen késést. Ez különösen érvényes a kis online szolgáltatásokra.
Az egy helyen való vásárlás, a több adatbázisban való keresés, a duplikátumok kiszűrése és a kifinomult és hatékony keresőgépek vonzása jó ok marad arra, hogy az adatbázisokat "szupermarketekben" is kínálják a tartalomszolgáltatók által való publikálás mellett. A használóknak azonban össze kell hasonlítaniuk a különböző hostoknál elérhető adatok naprakészségét.
Az ilyen összehasonlítások esetén figyelni kell arra, hogy minden hostnál ugyanaz-e a forrásfájl. Egyes hostok például nem használják a MEDLINE-nak a nem angol nyelvű részhalmazát, amely drámai módon növelheti a naprakészséget, figyelembe véve, hogy milyen soká lehet hozzájutni az idegen nyelvű primer dokumentumokhoz.
Ha különböző adatbázisok frissességét összehasonlítják, különösen figyelni kell arra, hogy az almát almával hasonlítsuk össze. A hetente aktualizált adatbázisok nyilvánvalóan frissebbek, mint a havonta aktualizáltak, amelyek ugyanakkor a negyedévente frissítetteket múlják felül. Ezek a tényezők igazolhatják azonban, hogy miért az egyik adatbázist használják, s nem egy másik vele összehasonlíthatót. (Az, ha a tesztet azon a napon végzik el, amikor az egyik adatbázist épp aktualizálták, míg a másikat épp aktualizálás előtt áll, igazságtalanul torzíthatja az eredményeket.
A napilap adatbázisok összehasonlításakor észre kell venni, hogy a teljes szövegű változat valószínűleg közvetlenül bekerül az online szolgáltatásba, mielőtt a nyomtatott változatokat elkezdenék kinyomtatni. Azok az adatbázisok, amelyek jelentős mértékben adnak indexkifejezéseket az újságcikkek rekordjaihoz, mint például a National Newspaper Index, jóval lassabbak, mert az indexelés folyamata időbe telik. Azoknál az adatbázisoknál, amelyek referátumokat is szolgáltatnak (mint például a Bell & Howell cég Newspaper Abstracts Daily című szolgáltatása), valószínűleg nagyobb a lemaradás. Nem véletlen, hogy Husszein, Jordánia királya temetését követő napon a legtöbb rekordja a teljes szövegű digitális napilapoknak volt, amelyeknek anyagát közvetlenül az adatbázis-változatba töltik, és a legtöbb indexelő és referáló adatbázis nem is tudott a király elhunytáról.
A hírügynökségeket tekintik a legfrissebbnek az adatbázisok közül, de egy 1999. július 15-én elvégzett teszt azt mutatta, hogy nem minden hírügynökség volt percrekész, és a Canada Newswire adatbázis - amely napi többszöri frissítést ígér - 10 napos késésben volt a DIALOG-nál (4.38. ábra). Meg kell jegyezni, hogy az adatbázis-szolgáltatók az információt egy meghatározott moratórium (általában néhány óra) lejárta után kapják meg. 10 napos késés messze kívül esik minden moratóriumon. Az AP News, U. S. Newswire, AFP English Wire és az AFP French Wire egynapos lemaradásban volt, a PR Newswire két nappal maradt el. Csak a Japan Economic Newswire és a Canada Newswire volt jelentős mértékben lemaradva.
A napilapok definíciójuk szerint naponta jelennek meg, de ez nem jelenti azt, hogy szó szerint naprakészek egy harmadik fél online szolgáltatójánál. Egy gyors pillantás a DIALOG adatbázisainak Papers (Napilapok) kategóriájának szalagcímeire, bannereire, s máris benyomást szerezhetünk arról, mennyire frissek az adatbázisok. Sajnos a bannerek nem mindig tükrözik megbízhatóan az aktualizálás dátumát. Pedig úgy kellene lennie, mert az aktualizálás dátuma automatizált folyamat részeként adódik hozzá a bannerhez. Egy adatbázis aktualizálásának legmegbízhatóbb ellenőrzése az, ha olyan keresést folytatunk le, amelyben aznapi adatokra kérdezünk (vagy talán még az előző egy vagy két napra is).
Az 1999. december 23-án elvégzett ilyen keresés megmutatta, hogy a legtöbb napilap adatbázis valóban naprakész volt, s csak néhány késett egy vagy több napot. A San Jose Mercury tűnt a leginkább késésben levőnek. A banner a legutóbbi aktualizálás dátumaként 1999 december 18-át jelölte meg. Az aktualizálás mezőjében az UD=19991223, UD=1991222 és az UD=19991221 keresés azt igazolta, hogy azt utoljára 1999 december 21-én aktualizálták (4.39. ábra) - nem túl jó egy, a Szilícium-völgyből származó napilap számára, de nem olyan rossz, mint amit a banner sugall. Tapasztalataim szerint a bannerek dátumai körülbelül az esetek 80 százalékában pontosak a DIALOG-nál az összes olyan adatbázisra vonatkozóan, amely tartalmaz könyvtár- és információtudományi anyagot tartalmaz.
Az Ovid rendszer használói már belépéskor látják, mennyire frissek az adatbázisok, mert az adatbázisok listája a dátum bannerrel együtt automatikusan megjelenik (4.40. ábra). (Az Ovid kérésre e-mail üzeneteket is küld az adatbázisok frissítéséről.) A SilverPlatter és az H. W. Wilson cégeknek hasonló nyitó képernyőjük van, amely információt ad a használóknak az adatbázisok frissítésének helyzetéről (4.41. és 4.42. ábra). A DIALOG-ban az adatbázisok és a bannerek kilistázása nem automatikus, a használónak kell kezdeményeznie az adatbázisok kiválasztásával és a SHOW FILES paranccsal (4.43. ábra).

4.38. ábra: A hírügynökségi adatbázisok listája az aktualizálás bannerével

4.39. ábra: Az aktuális nap feldolgozottságának ellenőrzése a napilap-adatbázisokban.

4.40. ábra: Részlet az Ovid adatbázis listájáról a dátumok bannerével.

4.41. ábra. Részlet a SilverPlatter adatbázis listájáról a dátumok bannerével.

4.42. ábra. Részlet az H. W. Wilson cég adatbázis listájáról a dátumok bannerével.
A korábbi képernyőképek azt is illusztrálják, milyen különbségek vannak az adatbázisok frissítésének lemaradásában a különböző hostoknál. Nem meglepő, hogy a fájl előállítójának változata volt a legfrissebb az H. W. Wilson cég Biological & Agricultural Index, Art Abstracts, Applied Science & Technology, továbbá a Business Abstracts esetében. A Business Abstracts, Biological & Agricultural Index és a Humanities Abstracts esetében az Ovid és a DIALOG azonos volt, a Readers' Guide Abstracts esetében az Ovid jobb volt a DIALOG-nál, míg a DIALOG volt jobb az összes többi fájlnál az 1999 júniusi frissítéseknél.

4.43. ábra: Részlet a DIALOG adatbázisainak listájáról a dátumok bannerével.
Egy adatbázis frissítésének következetessége természetesen alapkövetelmény a rekordok megfelelő időben való elérhetőségéhez. Ha megnézzük az aktualizálás indexét, ez némileg fényt derít az alkalmazott mintára, de nem mondja el a teljes történetet. Az (update, aktualizálás) mező értéke jelzi az adatbázishoz adott rekordok halmaza esetében az évet és hetet, hónapot vagy negyedévet, vagy csak a tervezett aktualizálási dátumot. Néha ez egybeesik a tényleges aktualizálási idővel, néha nem. Mindazonáltal az UD index váratlan hézagokat mutathat.
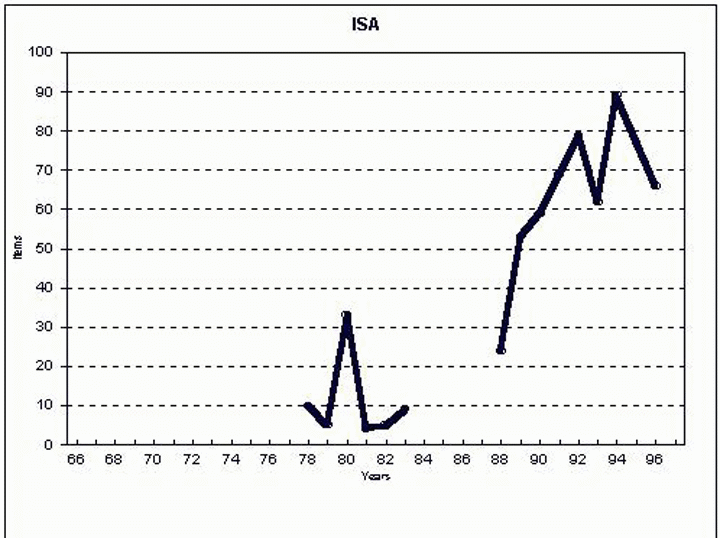
Ez a helyzet az ISA adatbázis esetében, amely, bár évi 11 aktualizálást ígért, arra csak 8 alkalommal került sor 1999-ben (4.44. ábra). 2000 elején az ISA bejelentette, hogy az adatbázis aktualizálásainak számát évi 11-ről 9-re csökkentik; körülbelül 6 hét különbség lesz köztük. Ez vágyálomnak bizonyult. Az adatbázis aktualizálása még rendszertelenebb, ötletszerűbb volt 2000-ben, mint azelőtt. 2000 novemberéig az ISA-t hatszor aktualizálták, s nem egyenletes megoszlásban.
A LISA (4.45. ábra) és a Library Literature (4.46. ábra) adatbázisokat 12 alkalommal aktualizálták 1999-ben, s a frissítések nagyon rendszeresek voltak mindkét adatbázis esetében. 1998-ban azonban a LISA is komoly hézagokat mutatott. Az UD mezők szerint nem került sor aktualizálásra januárban, februárban, áprilisban, májusban, júniusban és novemberben, a márciusi aktualizálás is minimális volt (4.45. ábra). A Library Literature-t mind 1998-ban, mind 1999-ben az előre tervezett ütemben aktualizálták (4.46. ábra).

4.44. ábra: Az ISA aktualizálásának mintája 1999-ben.

4.45. ábra: A LISA aktualizálásának mintája 1999-ben.
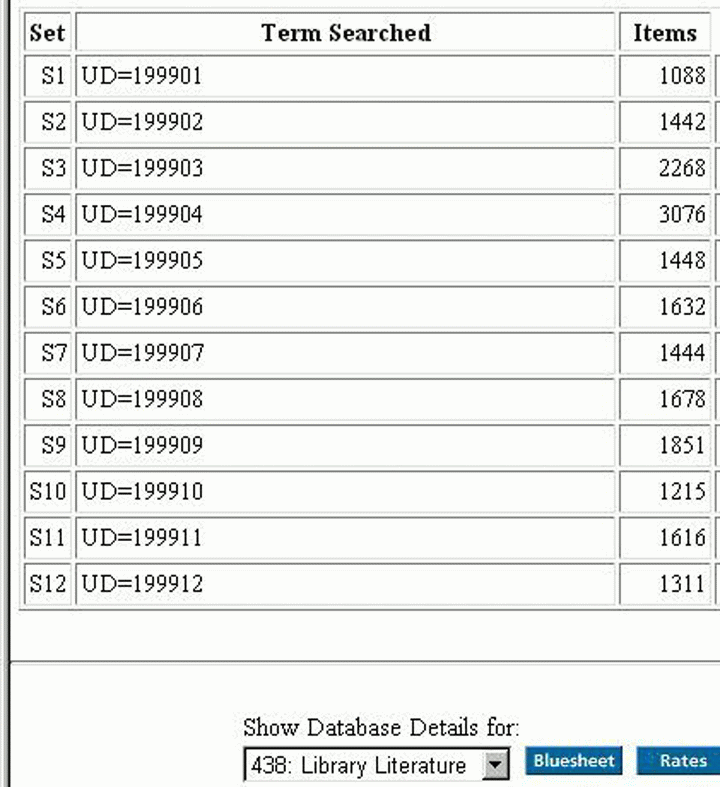
4.46. ábra: A Library Literature aktualizálásának mintája 1999-ben.
Azok számára, akik adatbázisaikat rendszeresen aktualizálták, az UD index megbízható jelzője volt az aktualizálás mintájának. Egyes adatbázis-készítők azonban kihagynak egy vagy több hónapot az aktualizálásból, aztán pedig egyszerre szolgáltatják több hónap anyagát, hogy utolérjék magukat. Az adatbázishoz adott rekordok esetében az UD mezőket ahhoz a hónaphoz igazítják, amikor az aktualizálást el kellett volna végezni. Ezek után a használó nem tudja megmondani, hogy az aktualizálás mintája valóban olyan volt-e, amilyennek tűnik. Ez ahhoz hasonló, mint amikor egy bébiszitter a tervezett öt vagy hat etetést elmulasztja, végül az összes ételt egyszerre lenyomja a bébi torkán este 10-kor, mielőtt a szülők hazaérnek. Így a bébi megkapott minden ételt, ami járt neki arra a napra, vagy nem?
A Database hasábjain Allcock (1997) és Jacsó (1997c) között lefolyt vita után a DIALOG számos adatbázisában bevezette a ZD mezőt. Ezt automatikusan generálják, amikor az adatbázist ténylegesen aktualizálják. Tükrözi a pontos dátumot és az adatbázishoz adott rekordok számát. Az UD és a ZD indexek tételeinek összehasonlítása hajszálpontosan megmutatja a különbségeket (4.47. ábra). Az ISA esetében a januárban esedékes aktualizálásra április 9-én került sor, a februárira május 20-án, a márciusira június 7-én és így tovább. A májusi aktualizálást kihagyták, és minden bizonnyal a júliusi volt az eleve kihagyásra szánt hónap. Ezt használhatták volna fel arra, hogy valamennyire behozzák a lemaradást és növeljék az új rekordok mennyiségét, amely alig volt több az előző évek 50 százalékánál.

4.47. ábra: AZ ISA UD és ZD indexei értékeinek összehasonlítása a tényleges
aktualizálási minták megállapítása érdekében
Még egy "sikítóan tökéletes" aktualizálási minta sem garantálja a kurrens információt. Lehetséges, hogy egyes adatbázisokban egy adott év második vagy harmadik aktualizálása sem tartalmaz egyetlen rekordot sem abból az évből, még ha az aktualizálásra havonként is kerül sor. Másik oldalról azonban más havonta aktualizált adatbázisok esetében már az első aktualizálás is tartalmazhat cikkeket, amelyeket abban az évben adtak ki. A 4.48. és 4.49. ábra egyrészt a három könyvtár- és információtudományi adatbázis, másrészt a Social SciSearch és a Trade & Industry adatbázisok könyvtár- és információtudományi részhalmaza 1999-es teljes aktualizálási korpuszának összetételét illusztrálja. A diagramok megmutatják, hogy a rekordok mekkora százaléka vonatkozott az adott év dokumentumaira, az előző éviekre, a két évvel azelőttiekre és a régebbiekre. Az ISA-hoz hozzáadott rekordok csekély mennyisége különös figyelmet érdemel, mivel az körülbelül 30%-a az előző évek aktualizálási mennyiségének.

4.48. ábra: A rekordok megjelenési év szerinti megoszlása a könyvtár- és információtudományi
adatbázisok 1999-es aktualizálásaiban.

4.49. ábra: A rekordok megjelenési év szerinti megoszlása a könyvtár- és információtudományi anyagot
tartalmazó adatbázisok 1999-es aktualizálásaiban.
Az időbeli elmaradás mérésének másik módja megfelelő nagy mintán az, hogy kiválasztjuk egy adott évben publikált rekordok ezreit vagy akár tízezreit, s meghatározzuk, milyen az aktualizálási évek megoszlása azokra a rekordokra vonatkozóan - azaz, mennyit adtak hozzá közülük az adatbázishoz a megjelenés évében, egy évvel később, két év múlva, három év múlva vagy akár több évvel később. A 4.50. és 4.51. ábrák ennek a technikának az eredményeit illusztrálják az ISA és a LibLit összehasonlításával. A LISA nem volt használható erre a tesztre, mert 1997 novembere és 1998 júniusa között számos aktualizálás anyagát vonták össze egyetlen nagy tétellé (UD=199711-199806) az UD indexben, ez 7905 rekordot tartalmaz. Ez azt jelenti, hogy nem volt mód arra, hogy meghatározzuk az 1997 novembere és 1998 júniusa közti aktualizálás különbségeit, vagy bármely dátumét a kettő között.
Mindig ellenőrizni kell az ilyen egyedi sajátosságokat, mivel komolyan torzíthatják az eredményeket. A LibLit adatbázisra vonatkozóan csak azokat a rekordokat elemeztük, amelyekben megvolt a ST=NEW RECORD mező értéke, mivel az H. W. Wilson cég jelentős rekordellenőrző műveletet hajtott végre (de nem a kurrens tételek rovására). Néhány kisméretű korrekciós futtatásnak nincs hatása az eredményekre.

4.50. ábra: Tesztkérdés a publikáció évéhez képesti aktualizálás késés meghatározására az ISA-ban

4.51. ábra: Az aktualizálás késése a publikáció évéhez képest a LIBLIT adatbázisban.
Az igaz, hogy a következő évben való aktualizálás egészen más dolog egy olyan publikáció esetében, amely decemberben jelent meg s a következő januárban került be az adatbázisba, mint amelyik 1997 februárjában jelent meg és a következő év novemberében került be az adatbázisba. Ha sok rekorddal dolgozunk, akkor az ilyen szélsőségek kiegyenlítődnek.
Az ilyen technikák vonzereje az, hogy nagyon könnyű finomítani a halmazt és megismételni a keresést. Csak néhány percbe telik, ha ellenőrizni akarjuk például azt, hogy van-e különbség a késés mintájában a konferencia-előadások és a folyóiratcikkek között, vagy az angol nyelvű és az idegen nyelvű rekordok között.
Érdemes ilyen megkülönbözetéseket tenni, mert egy nemzetközi adatbázis, mint amilyen a LISA, sok folyóiratot dolgoz fel fejlődő és kevésbé fejlett országokból. Ezekben az esetekben a késések nagy része a forráspublikációk késői megjelenésének tulajdonítható (például a januári szám áprilisban jelenik meg). A folyóiratok postai küldéséből adódó késések is jelentősek lehetnek. Természetesen az USA-ban megjelenő kiadványok, különösen a tudományos folyóiratok, köztük a könyvtár- és információtudományiak, szintén gyakran késnek. Néha a késés olyan nagy, hogy a kiadó két számot összevon (spórolva a postaköltségen, de nagy gondot okozva az időszaki kiadványok számbavételében).
Arra is figyelni kell, hogy ne számítsuk be a korrekciós rekordokat, amelyek az eredeti rekordnál hónapokkal később jelenhetnek meg egy adatbázisban. Ez akkor lehetséges, ha a korrekciós rekordokat valamilyen speciális szimbólummal jelölik meg az aktualizálás dátuma után, mint az UD=9902C esetben, vagy speciális mezőt használnak, ahogy az H. W. Wilson cég teszi az ST=NEW RECORD (új rekord) és az ST=REVISION OR CORRECTION RECORD (revideált vagy korrigált rekord) indextételekkel.
Még egy másik lehetőség a késés megállapítására a folyóiratok szintjén az, hogy annak az adatelemnek a számait használjuk, amely a rekordok létrehozásának és bevitelének évét azonosítja. Az ilyen adatelemek nem elérhetőek minden adatbázisban, néhányban azonban igen. Az Information Science Abstractsben például a BN adatelem első két számjegye az adatbázis nyomtatott változatának évét mutatja, így nagyon könnyű rekonstruálni, hogy milyen késéssel vittek be az adatbázisba rekordokat olyan folyóiratokból, amelyeket az IFI/Plenum magfolyóiratoknak mondott.
Az RQ című folyóiratból származó eredmények halmazának az aktualizálás éve szerinti rangsorolása az aktualizálás mintáinak kimutatása érdekében (4.52. ábra) nem kelti azt a benyomást, hogy a lap a magfolyóiratoknak kijáró kezelésben részesült volna. Csak 1990-től dolgozzák fel (ebből az évből csupán hat rekord került be belőle az adatbázisba jókora késéssel), azután semmi 1994-ben, s újra csupán 4 rekord 1996-ban. Az ISA adatbázis fő jellegzetességeinek értékelésekor Jacsó (1998a) az RQ-t használta olyan folyóirat példájaként, amelynek teljesen dilettáns kezelése különös egy magfolyóiratnak tekintett tételnek is. Az RQ-ból (és néhány más magfolyóiratból) származó rekordok 1997-ben, 1998-ban és 1999-ben kerültek be - megkésve - az ISA-ba, így most egyes évek már jól fel vannak dolgozva (4.53. ábra).
Ez a késői hozzáadás magyarázza meg, miért került be olyan sok új rekord az RQ-ból ezekben az években, annak ellenére, hogy a folyóirat 1997 közepén beszüntette megjelenését ezen a címen. A hézagok sietős betömködése azonban nem növelte az adatbázis frissességét. Sok folyóiratból nem kerültek be új rekordok. A rekordok éves mennyisége rendkívüli mértékben csökkent, s 1999-ben minden idők legalacsonyabb értékét érte el.
Az RQ aktualizálási évének és kiadási évének mintája a LibLit adatbázisban sokkal kedvezőbb frissességet mutat (4.54. ábra). Ideális esetben az aktualizálás évét és a kiadás évét reprezentáló oszlopoknak csaknem azonosaknak kellene lenniük minden egyes évben. Ugyanaz az aszinkronitás, amit az RQ-val kapcsolatban láttunk, jellemző sok más "magfolyóiratra" is az ISA-ban, köztük a CD-ROM Professionalre, amely ugyancsak más címen jelenik meg 1996 utántól. Ahogy azt a 4.55. ábra mutatja, több rekord került be az ISA-ba 1997-ben és 1998-ban (a folyóirat ilyen címen való megszűnése utáni két évben), mint a megelőző hat évben összesen. Bár ez kétségkívül késői ébredés, jobb későn, mint soha.

4.52. ábra: Az RQ aktualizálási mintája az ISA-ban

4.53. ábra: Az RQ kiadási év mintája az ISA-ban

4.54. ábra: Az RQ tényleges aktualizálási éve és kiadási éve mintája a LibLit adatbázisban.

4.55. ábra: A CD-ROM Professional tényleges aktualizálási éve és kiadási éve mintája az ISA-ban.
Az adatbázisok naprakészsége kritikusabb kérdés, mint retrospektivitása, mivel a legtöbb használó számára a friss információ fontosabb, mint a történeti jellegű. A használók gyakran hajlandók is többet fizetni a kurrens információért. Ezt világosan illusztrálják az átíró, a műsorok írott szövegét nyújtó szolgáltatások árai, sokkal többet kérnek a friss TV- vagy rádióműsorok szövegéért, mint az egyhetes vagy egyhónapos anyagokért. Néha egy adatbázisnak mondjuk az 1966 és 1982 közötti retrospektív részhalmaza sokkal kevesebbe kerül, mint az 1983-1999-es szegmentum.
A címtár, enciklopédia vagy biográfiai adatbázisok esetében a frissesség ellenőrzésének legjobb módja az, ha megnézzük, hogy egy személlyel, céggel, országgal vagy folyóirattal kapcsolatos, valóban kurrens információk megtalálhatóak-e az adatbázisban. Például a legfőbb CD-ROM-os enciklopédiák esetében, amelyeket 1999 nyarának végén jelentettek meg, a frissesség tesztelésének egyik kézenfekvő módja, ha megnézzük, szerepeltek-e bennük az 1998-as Oscar-díjas filmek (1999 márciusában közölték), az 1999-es Pulitzer-díj nyertesei a dráma és költészet kategóriájában (1999. április közepe) és az NBA 1999-es bajnoka (az 1999. június 25-i mérkőzésen dőlt el, ki lesz). A három nagyközönségnek szóló enciklopédia közül egyikben sem voltak benne az 1999-es Pulitzer-díjak. A Compton's bizonyult a legfrissebbnek a másik két teszt alapján (4.56. és 4.57. ábra.) A Microsoft Encarta volt a második legjobb, ahol a Compton'shoz hasonlóan a friss adatok vonzóan megtervezett táblázatokba kerültek be (4.58. ábra). Meglepetésre a különben nagyon jó Grolier Encyclopedia volt messze a legrosszabb mindhárom tesztben. Az Oscar-díj címszónál 1990-től máig ígéri a listát, ám az utolsó lista az 1997-es (1998 márciusában bejelentett) győztesek névsora. A rosszul megtervezett táblázat más kérdés, de az is lehangoló volt (4.59. ábra)

4.56. ábra: Az 1999 nyarán megjelent Compton's 2000-ben benne voltak
az 1999 márciusában bejelentett 1998-as Oscar-díjas filmek.

4.57. ábra: Az 1999 nyarán megjelent Compton's 2000-ben benne volt az NBA 1999-as NBA bajnok.

4.58. ábra: A Microsoft Encarta 2000-ben benne voltak az 1998-as Oscar-díjas filmek

4.59. ábra: A Grolier 2000-ben csak 1997-ig voltak benne az Oscar-díjas filmek.
Az online adatbázisok és online enciklopédiák előnyben vannak, mert folyamatosan és elég gyakran aktualizálhatják őket. A Jordánia királyára, Husszeinre vonatkozó tételeket három hónappal halála után néztem meg, majd minden azt követő hónapban, ez volt az egyik teszt, amit a frissesség ellenőrzésére használtam. Különösen kiábrándító volt, hogy az A&E Biography adatbázis (http://www.biography.com) még 10 hónappal halála után sem aktualizálta a tételt (4.60. ábra), s nem volt tisztában hat 1999-ben elhunyt Nobel-díjas közül ötnek a halálával.

4.60. ábra: Husszein király elavult életrajza 1999 végén.
Persze minden relatív. A Columbia Encyclopedia harmadik kiadásának az Electric Library-ben található változatában Husszein király uralkodik, Frank Sinatra énekel, Sir Georg (nem George) Solti vezényel 2000 szeptemberében. Az ötödik kiadás, amelyet 2000 márciusában váltott fel a hatodik kiadás, szintén elérhető ingyen az Information Please weboldalán keresztül (http://www.infoplease.com), itt friss információ volt található minden teszthez kapcsolódóan. A legtöbb használó csak a "Columbia Encyclopedia" logót látja, s feltehetőleg nem tud a két verzió frissességbeli (és egyéb) különbségeiről. Sok használó örökké peches maradt volna, mert begépelve magát az encyclopedia szót URL-ként (akár a www előtag és a com szuffix utótag nélkül) az enciklopédia Electric Library-beli változatához jutottak el, amelyet szerencsére szintén frissítettek 2001-ben és amely a Columbia Encyclopedia 6. kiadásának változtatás, rövidítés nélküli szövegét kínálja.


