
7. Pontosság
Az adatbázisból visszakeresett információk pontosságát gyakran természetesnek veszik. Sok használó számára az a tény, hogy az információt nem csak papíron szolgáltatják és prezentálják, hanem számítógépen is, extra hitelességet ad a CD-ROM-os és online adatbázisoknak. Az elmúlt 30 évben a nyomtatott output növekvő mértékben volt a számítógépes adatfeldolgozás mellékterméke. Az adatbázisok aligha lehetnek pontosabbak, mint a belőlük származó nyomtatott változatok. Sok más adatbázist pedig csak nyomtatott formában létező adatokból hoztak létre. A nyomtatott adatok számítógépes feldolgozása további hibákat hozhat és hoz is. Ezek közül van, amit technikai nehézség okoz, például amikor a szkenner/konverziós szoftver nem ismer fel pontosan egy betűt vagy egy számot.
Amikor az adatokat manuálisan viszik be a nyomtatott szöveg, katalóguscédulák, űrlapok és kérdőívek alapján, nagy számban fordulnak elő további hibák. Bár igaz az, hogy megvan a lehetősége annak, hogy kifinomult adatbevitel-ellenőrző programokat használjanak, kevés fájlelőállító kíván erre költeni. Amikor visszamenőlegesen elvégzik az ellenőrzést, a megtalált és javított hibák mennyisége elképesztő.
Ez világosan látható olyan katalógusrekordoknál, amikor manuálisan vitték be az adatokat katalóguscéduláról vagy magából a primer forrásból. A probléma méretét jól illusztrálja az OCLC, amely napi 30000 javított hibát jelentett Online Közös Katalógusának takarításakor. Bár ez a szám mindenféle típusú hibát tartalmazott, így például kódolási hibákat és elírásokat is, nagysága még így is megdöbbentő.
A nyomtatott primer források felelősek sok hibáért. A közönség ritkán tud róluk, hacsak a hiba nem okoz kárt és nem teszi szükségessé egy könyv visszavonását. Az American Libraries (1996) jelentett számos ilyen esetet. Például ez történt Carol Walter Great Cakes (nagyszerű torták) című művével, amelyet kiadója, a Ballantine visszavont, "mert egy recept a hozzávalók között felsorolt egy mérgező virágot, a májusi gyöngyvirágot". Valóban nem egészséges recept. "Csak" intellektuális kárt okozott volna egy történelmi tankönyvsorozat, amelynek több mint 20 millió dollár költséggel járó bevezetését már fontolgatták Texasban, amikor a könyv megvásárlása előtt egy jogvédő civil szervezet több mint 5200 hibát fedezett fel benne.
Dr. Ruth egyik könyvét azért vonták vissza, mert két olyan időszakot, amelyet a terhesség elkerülése szempontjából nem biztonságosként határozott meg, a végső változatban "biztonságos"-ra cseréltek. Pedersen (1992) a Publishers Weekly című lapban számolt be egy olyan tankönyv visszavonásáról, amely azt állította, hogy Truman elnök "könnyen befejezte" a koreai háborút az atombomba ledobásával.
Elég sokatmondó az, hogy az összes 3244 rekord közül, amelyet a New York Timesból a Newspaper Abstracts Daily adatbázishoz 1999 januárjában hozzáadtak, 121 volt egy korábbi számban megjelent információ korrekciója. Nem mindegyik volt világrengető hiba, de elég komoly volt ahhoz, hogy a New York Times szükségesnek tartsa javítását. Egy gyors keresés alapján a hibáknak az új rekordok számához viszonyított aránya a Washington Post (2114-ből 15), a Wall Street Journal (4117-ből 16) és a Los Angeles Times (1153-ból 10) esetében sokkal alacsonyabb volt, de ez kapcsolatban lehet az újságok eltérő korrekciós gyakorlatával is.
Meglepő, hogy milyen nyilvánvaló hibák kerülhetnek be vagy származhatnak még könyvtárosoktól is, akik pedig a pontosságot nagyra értékelik. Az American Libraries (1996) szerint egy, 1996-ban a Chicago Public Library által összeállított történeti kalendárium első kiadásában olyan hibák voltak, mint Michael Jordon Michael Jordan helyett, Lord Tenneyson Lord Tennyson helyett, míg Jean Baptiste Point du Sable-nak mind a születési, mind a halálozási dátumát 1818-ra tették. Keveseknek (ha egyáltalán vannak ilyenek) lehetnek olyan eredményeik újszülöttként, hogy kiérdemeljenek egy helyet egy kalendáriumban.
A kalendárium két különböző évet is megadott Richard Daley első alkalommal való megválasztásaként. A politikában bármi lehetséges, de nem valószínű, hogy Richard Daley-t kétszer választották volna meg első alkalommal, még akkor sem, ha figyelembe vesszük Chicago változatos választási történetét. Hibák nagy számban fordulnak elő szépirodalmi és ismeretterjesztő művekben is, köztük a gyerekeknek szóló életrajzokban. Ahogy egyre több nyomtatott anyagból készül online adatbázis, a digitális változatok terjesztik a hibákat.
A helyesírási hibák és elírások az adatbázisok pontatlanságainak legáltalánosabb típusai. Online katalógusokat elemeztek a leggyakrabban, hogy felfedezzék a pontatlanságok változatait. O'Neill és Vizine-Goetz alapos elemzést adott erről a szakirodalomban 1988-ban. Az elírások problémájának nagysága szembetűnő. Klemmer és Lockhead (1962) úgy találta, hogy a hibák mértéke 2 és 6 között van 10000 leütésenként. A Pollock és Zamora (1975) által a Chemical Abstracts Service adatbázisában végzett mérés szerint a szavakban számított hibaarány relevánsabb lehet, mert egyetlen hiba egy szóban egy rekordot visszakereshetetlenné tehet.
Minden 1000 szó között 2 elírtat találtak ebben a drága adatbázisban. Azt is megállapították, hogy a hibák 90-96%-a a négy legáltalánosabb hibatípusba tartozik: karakter(ek) kihagyása: 30-40 százalék; karakter(ek) beillesztése: 25-35 százalék; karakterek cseréje: 15-20 százalék; és felcserélése: 10-15 százalék.
Tudományos forrásokról van szó, amelyek legtöbbje átmegy lektoráláson és szerkesztésen, ezek feltételezhetően hozzájárulnak ezen folyóiratok magas költségeihez és szakmai nagyrabecsüléséhez. A nagyközönségnek szóló források, például a napilapok helyzete minden bizonnyal rosszabb.
A hibák legalaposabb, Yannakoudakis és Fawthrop (1983) által végzett elemzése feltárta, hogy sok hibát követnek el a magánhangzókkal, s azokkal a szavakkal, amelyekben a w, y és h betűk szerepelnek. A dittográfia és a haplográfia (olyan betűk megduplázása, amelyekből csak egynek kellene lennie és betűk kihagyása, amikor duplán kellene szerepelniük, például olyan hibák, mint leter dupplication) nagyon általános. A hibatípusok és minták részletes elemzése nagyon hasznos lehet a defenzív keresési stratégiák kifejlesztéséhez.
Az 1990-es évek végén a problémát enyhítette sok online katalógusban az automatikus hiba ellenőrző és -korrigáló műveletek bevezetése, de a referáló és indexelő szolgáltatások nem alkalmazták kellő mértékben az eljárást. A legendásan tiszta Western Library Network (WLN; korábban Washington Library Network) bibliográfiai adatbázisának és az OCLC-nek az 1999-es összeolvasztása valószínűleg segíteni fogja az OCLC jelentős tisztítási próbálkozásait. Az is jó jel, hogy több adatbázist építenek úgy, hogy közvetlenül a fájl előállítójától veszik át a fájlokat. A közvetlen adatbevitel csökkenti a bibliográfiai hivatkozások, referátumok és a teljes szöveg újragépeléséből származó további hibák előfordulását. Ez különösen igaz a korábban idézett tanulmányok fényében, amelyek azt állítják, hogy a legtöbb gépelési hiba a QWERTY billentyűzet használatával függ össze. Valamennyire ironikus, hogy a sokkal jobb Dvorak billentyűzet, amely a tesztek szerint drasztikusan csökkenti a gépelési hibákat (és a carpal tunnel szindrómát), sohasem terjedt el.
A referáló és indexelő adatbázisokban előforduló helyesírási hibákat már nagyon korán, 1977-ben vizsgálta Charles Bourne az adatbázis szolgáltatójának szoftverének használatával. 3600 indexfogalmat (tárgyszavakat, valamint a referátumokból és a címekből származó szavakat) vizsgált 11 különböző adatbázisban. Az elírt indexfogalmak aránya a BIOSIS 0,4%-ától az ABI/INFORM 22,8%-áig terjedt, a továbbiak közül az ISMEC (Information Service in Mechanical Engineering) (0,6%); ERIC (4,2%); Social Science Citation Index (6,1%) és NTIS (6,5%) voltak az alacsony tartományban és a Predicast PATS adatbázisa (12,4%) és a Compendex (12,3%) a magasban. Kicsit ironikusnak találtam, hogy a ISMEC elírva, ISMES formában szerepel Bourne cikke (1977) egyik ábrájának feliratában, egy alaposan lektorált és szerkesztett folyóiratban, az Information Processing & Managementben. Az ABI/INFORM később nagyarányú tisztítási folyamaton ment keresztül, amelynek keretében az elírások többségét megszüntették.
Jeffrey Beall a piszkos adatbázis teszteléséről talán kevésbé tudományos, de nagyon pragmatikus abból a szempontból, hogy képet kapjunk az adatbázisok helyesírásának pontosságáról, olyan gyakran elírt szavak használatával, mint a Wensday, goverment, grammer és egy tucat másik gyakran elírt szó, A Database Searcher szerint Harold Way (1988) számolta ki 14 adatbázis pontossági értékét Beall teszt-szavainak felhasználásával. Dwyer (1991) finomította Bourne és Beall módszereit, kiküszöbölve hiányosságait azzal, hogy kiszámolta ugyanazon szó elírt és helyesen írt változatainak arányát, ezt a módszert maga Bourne ajánlotta. Jacsó (1995) néhány szó pontos és elírt változatát ellenőrizte öt könyvtár- és információtudományi adatbázisban. Úgy találta, hogy a LibLIt rendkívül tiszta, míg a legtöbb hiba az ISA-ban található, majd az ERIC-ben. Az ISA az accommodat szógyököt több mint 200 rekordban írta el; majdnem a helyesen írt változatok 20%-ában.
Cahn (1994) továbbfejlesztette ezeket módszereket - többek között - annak vizsgálatával, hogy a rekord tartalmazta-e az elírt szót helyesen írt formában is, azaz csökkentve vagy megszüntetve a keresésre gyakorolt hatását. Újra csak érdekes megjegyezni, hogy a John Wiley kiadó által megjelentetett Harvard Business Review (egy nagy befolyással rendelkező folyóirat és nagyon drága tudományos folyóiratok kiadója) utcahosszal megelőzte a 13 másik adatbázist - a legtöbb hibát produkálva Cahn tesztjeinek többségében.
Ballard és Lifshin (1992) végignézte egy egyetem online katalógusának kulcsszó indexében mind a 117000 fogalmát, s elemezte a hibákat az adatmező, szófaj és hibatípus szerint. 1082 hibás indexfogalmat találtak. Mivel a könyvkatalógusokban való kereséskor a címmezőnek kitüntetett szerepe van, elég hervasztó, hogy a címmezőből generált fogalmak tették ki a hibák 60%-át. Szerencsére több mint felük az alcímben volt, amely kevésbé kritikus a böngészés és a keresés szempontjából. A pozitív oldalhoz tartozik az, hogy nem voltak hibák a tárgyszavak mezőjében, s a szerzői mezőnek csak 2%-ában voltak elírások. (nem világos azonban a cikk alapján, hogy a szerzői nevek pontosságát hogyan ellenőrizték.) A hibák típusok szerint való megoszlása hasonló volt ahhoz, mint amit az előzőkben bemutattunk.
A hibának a cím mezőn belüli helyét is elemezték. Rossz hír az, hogy a hibák több mint 14%-a a cím első szavában fordult elő, s csaknem 41% az első három szóban. Az elírt kezdő szavakat tartalmazó tételek drámai módon csökkentik annak valószínűségét, hogy egy könyvet a cím alapján történő böngészéssel meg lehessen találni. Az elírt második és harmadik szavak szintén csökkentik egy ismert tétel megtalálásának valószínűségét, de kisebb mértékben, ami attól is függ, hány rövid tételt jelenítenek meg a képernyőn és milyen messze van az elírt tétel a helyesen írttól. A több rövid tétel növeli annak esélyét, hogy a használó észreveszi az elírt tételt, és a helyesen írt változattól való távolság kisebb lehet, ha az elírás a szó végén van. Az elírt Jacsu közelebb van a Jacsóhoz, mint a szintén elírt Jascó. Ironikus módon, amikor a katalógusban leggyakrabban elírt szavakra utalnak, köztük a commerical, reseach és adminstration változatokkal, a szerzők felsorolják a government szót is, azaz a helyesen írt változatot. Ez újra csak a nyomda ördöge lehetett. Az ilyen átfogó, a teljes populációra vonatkozó tesztek rendkívül sok időt követelnek meg. A problémás szavak egy vagy több leggyakrabban elírt formáját és a helyesen írt változatát használó módszer elegendő lehet ahhoz, hogy benyomást kapjunk az elírások mértékéről. Kiindulásul érdemes ellenőrizni egy weblapról (http://www.sentex.net/~mmcadams/spelling.html) a leggyakrabban elírt szavakat, a helyesen írt változattal és a helytelen változat gyakorisági mutatójával együtt egy olyan adatbázisban, amelyet gyakran használunk (7.1. ábra).
7.1. ábra: A leggyakrabban elírt szavak.
Különbséget kell tenni azok között a mezők között, amelyek egy keresési szempont kizárólagos forrásai (mint például a kiadás országa) és az olyanok között, amelyek más mezőkben is megjelenhetnek. Az elírás a referátum szövegében nem olyan kritikus, mert a helyesen írt változat szerepelhet a címben vagy a tárgyszavakban (vagy mindkettőben). Ez a megkülönböztetés nagyon hasonló ahhoz, ami a kontrollált szótárt használó mezők és a szabad szöveges mezők között van. A Rorschach név elírása a referátumban nem probléma a PsycINFO adatbázisban (7.2. ábra), mert pontosan is előfordul a referátum első mondatában, így a rekord visszakereshető. Az elírt változat az MHA cím mezőjében (7.3. ábra) nem tetszetős, de mivel helyesen is szerepel az eredeti, spanyol nyelvű címmezőben, ez csak a szemet bántja, amennyiben az eredeti címmezőt (azaz a spanyol címet) is felhasználják a kulcsszavak indexének vagy az alapszótárnak a létrehozásához.
Még abban az esetben is, ha az elírt változat az egyetlen előfordulás a referátumban (mint a második rekordban), ez nem súlyos probléma, amikor a fogalom helyesen megjelenik a tárgyszavak mezőjében. Amikor az elírt változat, Rorshach az egyetlen formátum, amelyben a név megjelenik, a rekord visszakereshetetlenné válik a helyes névalak, Rorschach alapján (7.4. ábra). Olyan adatbázisok esetében, mint például az Inside Conferences, amelyekben nincs referátum s amelyek nagyon széles tárgyi kategóriákat használnak, a címben történő elírások végzetesek lehetnek. Öt rekordból kettőben a toxoplasma szót taxoplasma formában elírták a címben, ez látható a 7.5. ábrán. Az elírások hatalmas számának fényében üdvözölni kell azt, hogy egyes keresőprogramok okosabbá váltak, és vagy automatikusan korrigálják a használó által beírt szavakat, vagy felajánlják mind a betűrendben közel álló fogalmakat, mind a használó által beírthoz hasonlóan hangzó szavakat. Az előbbit a National Criminal Justice Reference Service adatbázisának a fájl előállítója által készített változatában használják; az utóbbit az Encyclopedia Britannica előfizetéses változatában használták 1999-ig.

7.2. ábra: A Rorschach névnek egy helyesen írt és egy elírt változata van a referátumban.

7.3. ábra: Helyesen írt változat az eredeti (spanyol) címben és elírt változat az angol címben.

7.4. ábra: A Rorschach név egyetlen előfordulása el van írva a referátumban.
Azoknál a mezőknél, amelyekben a lehetséges értékeknek korlátozott a száma, mint a nyelv, a kiadás országa vagy a dokumentumtípus, elég egyszerű ellenőrizni és kiszámolni a pontosság mértékét - a helyesen írt és az elírt változatot tartalmazó rekordok arányát. Könnyű is kijavítani egy hozzáértő fájl előállító számára, aki kellően tiszteli a használót. Egy adatbázis nyelvi indexe, amely viszonylag nem sok nyelven írt dokumentumokat tartalmaz, csak egyszeri áttekintést igényel, mivel a nyelvek száma általában egy-két tucat.
A hibás tételek nagy száma miatt a nyelvi index több képernyőre szóródhat szét, s emiatt a használó elveszíthet releváns rekordokat, ha nem veszi észre az elírt változatokat. Elég nyilvánvaló például az ISA nyelvi indexe alapján, hogy szükség lenne valakire, aki ellenőrizné, hogyan kell helyesen írni a Czech (cseh) szót. Ebben az esetben az elírások legalább közel vannak egymáshoz, de a helyes Serbo-Croatian (szerb-horvát) változat több képernyőnyire van a nem létező Croato-Serbian (horvát-szerb) nyelvtől (7.6. ábra).

7.5. ábra: A toxoplasma szó egyetlen előfordulása el van írva a címben.
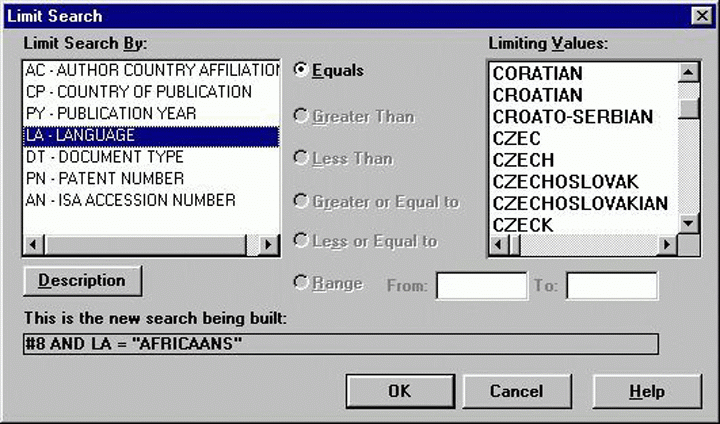
7.6. ábra: Elírások az ISA nyelvi mezőjében.
Míg a Portuguese (portugál) szó elírt változatai a helyesen írt mellett találhatók a 7.7. ábrán, az a tény, hogy a pontatlan változatok száma eléri a helyesen írtak felét, nem növeli az ISA adatbázis vonzását. Mindezek ijesztővé válnak az adatbázis DOS-os CD-ROM változatában, mert ebben a változatban a nyelvi index nem böngészhető (csakúgy, mint a kiadás országa vagy a dokumentumtípus mező sem). Ez elkendőzi a fogyatékosságot a használó elől, megfosztva őket portugál nyelvű dokumentumok tételeinek felétől, ha helyesen írják a nyelvet a kérdésben.
Egyes adatbázisok még ennél is rosszabbak, ott az elírt változatok száma ugyanennek a nyelvnek az esetében felülmúlja a helyesen írtakat. A 7.7 ábra mutatja a Portuguese elírt és helyesen írt változatainak megoszlását néhány adatbázisban 1999 februárjában. A FLUIDEX-ben (File 96) és a Pollution Abstractsben (File 41) közel háromszor annyi elírt változat van, mint helyesen írt. A PROMT adatbázisban (File 16) csupán 9-szer írták helyesen a Portuguese szót, 232 hibás mellett. Néha a helyesírási változatokat elfogadhatónak tekintik a szótárak, de a Portugese változat úgy rossz, ahogy van.

7.7. ábra: A Portuguese elírt és helyesen írt változatainak aránya a nyelvi indexben.
Miért keresné egy tipikus használó egy nyelv elírt változatait, ha egyes rekordokban valóban megtalálható a helyes változat? Ebből a szempontból a PsycLIT Compact Cambridge változata jobb, mert mind az 1375 rekordban elírták a Portuguese szót (a tény, hogy egyetlen rekordot sem talál, figyelmeztetheti a használót, hogy valami probléma lehet a nyelvi mezővel). Ugyanez érvényes az IAC két adatbázisára, az AeroSpace/Defense Markets Technologyra és a Marketing & Advertising Reference Servicesre amelyekben nincs egyetlen rekord sem, amelyben helyesen írnák ezt a nyelvet.
Ugyanez igaz a Mental Health Abstracts adatbázisra is. Nincs egyetlen rekord sem, amelyben az English szó helyesen szerepelne a nyelvi mezőben. Érdekes, hogy az adatbázis dokumentációja arra utasítja az indexelőt, hogy ha "a dokumentum nyelve angol, nem kell feltüntetni". Az ember kíváncsi, hogy vajon ezt a döntést az után hozták-e meg, miután csaknem 100 alkalommal nem sikerült ezt a nem túl nehéz szót helyesen beírni. Az a személy, aki a DIALOG adatbázis-leírását (bluesheetjét) írta az MHA adatbázisról az S LA=ENGLISH példát használva, minden bizonnyal nem tudott a döntésről, s nem tesztelte a mező használatára ajánlott példát. A használók, akik a nyelvi indexet böngészik, ha hajlandók képernyőt képernyő után görgetni, legalább láthatják a küzdelmet, hányféle módon lehet elírni az English szót (7.8. ábra). 1992-től az ISA megtanulta, hogyan kell a Portuguese szót helyesen írni; így mostanra kétszer annyi helyesen írt eset van, mint elírt.
Ha megvan a hozzáértés és a használó iránti tisztelet, akkor elérhető, hogy a nyelvi index teljesen tiszta legyen, ahogyan az a Library Literature-ben és az összes H. W. Wilson adatbázisban látható (7.9. ábra), Más kérdés, hogy miért található olyan sok rekordban az "undetermined" (meghatározatlan) változó a nyelvre vonatkozóan. Kiderül, hogy ezek mind könyvkritikákra vonatkozó rekordok, s a könyv eredeti nyelvére utalnak, nem pedig a kritikákéra. Az indexelő feltehetőleg kitalálhatná a könyv nyelvét a kritikából és megadhatná a megfelelő nyelvet a rekordban.

7.8. ábra: Az English szó nagyszámú elírása a Mental Health Abstracts adatbázis nyelvi mezőjében.

7.9. ábra: A nyelvek teljesen hibátlan névalakjai a LibLIt adatbázisban.
Nehezebb dolog szerzői nevek tízezreinek pontos helyesírását elérni, pedig ez sok adatbázis gondja. A pontos szerzői név alapvető fontosságú sok keresés esetében, és a legtöbb adatbázisban a pontos szerzői név nem vehető készpénznek (a névalakok következetessége még valószínűtlenebb). Az H. W. Wilson cég adatbázisai, a WLN bibliográfiai adatbázisa és az Internet Movie Database kiemelkednek hibátlan névrendszó-kezelésük (authority control) miatt, beleértve az egységes névalakok. Bár a Kongresszusi Könyvtár (LC) az elsők közé tartozott az egységesített névalakok kifejlesztésében és alkalmazásában, ezeknek is vannak hiányosságaik. Az LC authority fájljában előforduló hibák azért súlyosak, mert bekerülnek minden olyan katalógusba, amely az LC MARC rekordokat használja. Lehangoló látni, hogy F. W. Lancaster egyik keresztneve hibás formában (Wilfred) szerepel az LC authority fájljában, a helyes Wilfrid mellett.
A szerzők vagy más személyek neve pontosságának tesztelése egy adatbázisban nem lehet mindenre kiterjedő, mert még a kis adatbázisokban is túl sok név szerepel. Nehezebb is mintát venni, mint a szabad szöveges mezők vagy a legtöbb kontrollált szótáras mező pontosságát ellenőrizni, hacsak nem rendelkezünk abszolút megbízható forrással a személynevekről. Jacsó (1989) Rolodexéből vett névjegykártyákat és a Columbia Egyetem Könyvtárosképzőjének (School of Library Services of Columbia University) katalógusában szereplő neveket használt, hogy ellenőrizze ismerősei és oktatókollégái nevét a könyvtárosok és információs szakemberek címjegyzékében (Directory of Library and Information Professionals).
Összesen 469 személyt keresett név alapján, de ezzel a megközelítéssel csak a könyvtárosok és információs szakemberek kevesebb mint felére vonatkozóan talált rekordokat. Egy más szempontok szerinti kiegészítő keresés valamivel növelte a találatok számát és feltárta, hogy az adatbázisban gyakori a nevek elírása. Olyan további keresési szempontok, mint a személy munkahelye, nem következetesen elérhetők és/vagy elavultak ebben az adatbázisban, ezért nem lehet azokra számítani tartalékként, ha a nevek szerinti keresés nem hoz eredményt. Ennek a címjegyzéknek a sok elírása még a szokottnál is fájdalmasabb, mivel az adatbázis az American Library Associationnel együttműködésben készült.
A Columbia Egyetem két oktatójának (tíz közül) az esetében az elírások végzetesek voltak, mert az első betűben követték el őket (Fres, Beth Eres, Beth helyett és Tetherbridge, Guy Petherbridge, Guy helyett.) Más pontatlanságok a név végénél voltak, így azokat a csonkolás alkalmazásával enyhíteni lehetett. Ebben az adatbázisban a személynév az egyedüli adatelem, amely minden rekordban jelen van; azaz bármilyen hiba elérhetetlenné teheti a rekordot.
Ebben a példában a fájl előállítója a felelős a pontosságért, de nem mindig ez a helyzet. A fájlok előállítói nem hibáztathatók, ha az eredeti forrásdokumentumban írtak el egy nevet. A Serials Review-nak sikerült kétszer a Jacsó nevet Jascó formában elírnia (7.10. ábra) annak ellenére, hogy a szerző nem éppen halk szavúan tiltakozott ez ellen az első eset után. Mivel a lektorált folyóiratok kiadói nem fizetnek a szerzőknek, az egyetlen ellenszolgáltatás (jutalom) az lehet, ha elismerik és idézik őket, de amikor a szerző nevét rosszul írják, még ez az ellenszolgáltatás is elvész.
A Serials Review lektorált folyóirat, de olvasószerkesztői munkája a szerzői kézirat munkafázisainál kevésbé rigorózus folyamat. Kivételes az, hogy az H. W. Wilson bibliográfiai rekordjában mindkét fenti esetben kijavította a szerző elírt nevét, s a LISA is egy esetben. Nagyon egyedi és könnyen megkülönböztethető nevek kis mintájának átnézése a szerzői indexben jól jelezheti a szerzői nevek pontosságát.
A több adatbázisban végzett keresés eredményei illusztrálják e szerző nevének leggyakrabb elírási formáit (7.11. ábra). Meglepő módon még olyan adatbázisokban is, amelyek törődnek a minőséggel, mint például a Microcomputer Abstracts, viszonylag magas az elírások száma ebben a mintában.

7.10. ábra: Pontatlan névalakok a forrásdokumentumban, a Serials Review-ban.

7.11. ábra: A szerző neve leggyakrabban elírt változatának gyakorisága.
Az Institute for Scientific Information nem vádolható a hivatkozott szerzők nevének elírásával (és a más szempontból pontatlan hivatkozásokkal), ha az eredeti dokumentumban írták el a hivatkozási elemeket. Az előléptetésre váró oktatók aligha engedhetik meg maguknak, hogy nevük 15 rekordban el legyen írva (7.12 ábra) ebben az irigyelt adatbázisban - különösen hivatkozott szerzőként, ami fontosabb, mint a közreműködő szerzői szerep. Ez csaknem a 20%-át reprezentálja azoknak a tételeknek, amelyek idézik a szerzőt. Az ember csak találgathatja, milyen arányban írhatják el a valóban hosszú thai vagy különösen a lengyel neveket, amelyekben sok a mássalhangzó.
Annak, hogy a szerző neve alapján nem találunk meg egy rekordot, sokkal súlyosabb következményei lehetnek annál, mint hogy egy tételhez nem jutunk hozzá. Pao (1989) azt tapasztalta, hogy a MEDLINE adatbázisban 4,5%-os a szerzői nevek elírásának (és következetlenségeinek) aránya. Az eredmény világosan bizonyította, hogy az elírások aránya olyan mértékben torzította a szerzők produktivitásának eloszlását, hogy az többé nem felelt meg Lotka eloszlási törvényének. Miután az elírt neveket nagy munkával kijavították, az eloszlás újra megfelelővé vált.
Nyilvánvaló, hogy a szerzők nevének elírásai jelentősen befolyásolhatják az előléptetéseket, kinevezéseket, pályázatokat és az oktatók produktivitás szerinti rangsorolását, ha az adatbázisokból kinyert adatokat ellenőrzés nélkül fogadják el. Azok a személyek, akiknek összetett nevük van, előtag van a nevükben vagy csak kis mértékben is szokatlan a nevük, különösen hátrányban vannak ebből a szempontból. A központozás különbségei, a nagybetűs írásmód, az előtagok hátravetése szétszórja nevüket az indexben, azokon a problémákon felül, amelyeket az egyszerű nevekkel is előforduló felcserélések okoznak.

7.12. ábra: A Jacsó név elírt és helyesen írt változatai szerzőként
és hivatkozott szerzőként a Social SciSearch adatbázisban.
Míg a folyóiratcímek elírása nagyon gyakori, helyesírásuk és rövidítéseik következetlensége még gyakoribb, ezért ezzel a kérdéssel a következő fejezetben foglalkozunk.
Egy terület érdemel különös figyelmet: az eredeti dokumentumok hivatkozásainak pontatlansága. Ennek nyilvánvalóan komoly következménye van minden hivatkozási index számára, s kisebb mértékben minden teljes szövegű adatbázisra, amelyekben szerepelnek bibliográfiák és a jegyzetek. Smith (1981) a hivatkozási hibákkal foglalkozó gondolatébresztő tanulmányában majdnem 20 évvel ezelőtt figyelmeztetett arra, hogy a pontatlan hivatkozások eltorzíthatják a bibliometriai vizsgálatokból levont következtetéseket.
Pandit (1993) a hivatkozások pontosságát vizsgálta a könyvtár- és információtudomány olyan legmagasabban rangsorolt tudományos folyóirataiban, mint például a College & Research Libraries, Library Resources & Technical Services, Library Quarterly, Library Trends és a Journal of Academic Librarianship. Összesen 131 cikk 1094 hivatkozását vizsgálta. 193 hivatkozásban 223 hibát talált. A Library Resources & Technical Services és a College & Research Libraries című lapokban volt a legtöbb hiba (31,6% és 27,2%), míg a Library Trendsben csak 3,8% volt a hibaarány. Ironikus, hogy a Library Trends az egyetlen nem lektorált folyóirat (bár ez olyan időszaki kiadvány, amelyben csak felkérésre lehet szerepelni, s a legrangosabbak közé tartozik). A Library Trends a szokásos hibaaránnyal kap kéziratokat, de kivételesen gondos szerkesztéssel kijavítják a hibák többségét a végső kinyomtatás előtt, eszerint a vizsgálat szerint 92%-ukat.
Jelen könyv szerzőjének azt a hipotézisét, hogy a lektorált folyóiratok jobban figyelnek arra, hogy a szerzők igazodjanak lapjuk hivatkozási stílusához, mint hogy elérjék a hivatkozások tartalmának pontosságát, Pandit kutatásai megerősíteni látszanak. Természetesen a hivatkozási hibák egyes típusainak különböző súlya van. Ez a vigasz számunkra, könyvtárosok és információs szakemberek számára, akik láthatólag ugyannyi hibát követünk el a hivatkozásokban, mint az orvostudományi szerzők. A mi hibáink azonban Benning és Speer (1993) tanulmánya szerint valamivel kevésbé súlyosak. 555 hivatkozást vizsgáltak a Library Trends, Library Resources & Technical Services és a Bulletin of the Medical Library Association cikkeiben. Az 555 hivatkozás közül 525 elemzésének eredményeit összehasonlították az orvosi folyóiratok hivatkozási hibáival, és a hibaarány csaknem azonos volt a két csoportban (28% és 29%). A jelentős különbség az volt, hogy a hivatkozási hibáknak csak 2%-a tartozott a súlyos hibák közé a könyvtár- és információtudományi folyóiratokban, míg 7% volt az orvostudományi folyóiratok esetében.
Moed és Vriens (1989) öt orvosi folyóirat 4500 cikkének 25000 hivatkozását vizsgálta meg, s úgy találta, hogy a hivatkozások csaknem 10%-a tartalmazott legalább egy hibát. Az ilyen méretű elemzés túl van az egyszerű halandók kapacitásán, de a tanulság figyelmet érdemel. Érdekes, hogy mind Sweetland (1989) (aki gazdagon illusztrált szemlét készített a hivatkozási hibák irodalmáról), mind Moed és Vriens arra a következtetésre jutott, hogy a pontatlan hivatkozások gyakran arra a tényre vezethetők vissza, hogy a hivatkozó dokumentum szerzője nem látta a hivatkozott dokumentumokat.
A pontatlanságnak egy formája az is, ha nem igazodnak a nemzeti és nemzetközi katalogizálási szabályokhoz. Boissonnas (1979) 151 LC MARC rekordot és 150 OCLC rekordnak a tagok által beküldött inputját elemezte, amelyeket a Cornell Law Library katalogizálóinak módosítani kellett. Az LC rekordok csupán 29%-át és az OCLC tagok rekordjainak mindössze 1,3%-át találták olyannak, amelyek megfeleltek az AACR2, az ISBD és a publikált LC szabályok értelmezésének.
A címjegyzék adatbázisokban a hibák megtalálása nehezebb, ha nem ismerjük a szakterületet, hacsak nem nyilvánvalóak a hibák első pillantásra vagy az adatok nem tartalmaznak önellentmondásokat. Ez a helyzet a G. K. Saur cég World Databases adatbázisával, amelyben még a dokumentáció mintarekordjai is nonszensz adatokat tartalmaznak, s ugyanez érvényes az összes többi rekordra is, amelyeket e könyv szerzője megvizsgált (Jacsó 1998e) a könyvben említett adatbázisokra vonatkozóan. A ténybeli hibák mennyisége ebben az adatbázisban megdöbbentő. Az még megdöbbentőbb, hogy a jónevű fájl előállító és online szolgáltató továbbra is meglehetősen súlyos árat fizettet a gyanútlan használókkal ilyen hibás adatokért. Az egyetlen vigasz az, hogy - annak ellenére, hogy évenkénti aktualizálást ígértek, 1997 vége, az adatbázis első betöltése óta új rekordokat (és új hibákat) nem adtak hozzá. Általunk jól ismert folyóiratok rekordjainak megnézése komoly pontatlanságokat tárhat fel az időszaki kiadványok címjegyzékeiben. Az Ulrich's például halottnak (megszűntnek) nyilvánította a Computers in Librariest és a Multimedia Schoolst (az Information Today Inc. két folyóiratát) az adatbázis 1998 őszi kiadásában (7.13, ábra). 1999 téli kiadásában az Ulrich's mindkettőt visszahozta az életbe, miután rájött arra, hogy azok a téves információkat tartalmazó hírek, amelyek a két folyóirat haláláról szóltak, nemcsak koraiak voltak, de alaptalanok is. A folyóiratok előfizetőire mindez nem volt hatással, de a potenciális előfizetőkre talán igen. Az ember arra is kíváncsi, honnan származhattak a folyóiratok megszűnésére vonatkozó információk. Biztosan nem a kiadótól, amelynek feltételezhetően az információt kellett volna szolgáltatnia a Bowker számára. Nem tudhatjuk, hogy az egész adatbázisban ilyen mértékben vannak-e hibák, de biztosan érdemes a keresőknek mintákat venniük saját szakterületükön.

7.13. ábra: Hibás státusz információ az Ulrich's 1998 őszi kiadásában.
Szisztematikus hibafelderítés lehetséges a címjegyzékekben, legalábbis bizonyos adatelemekre. Az Egyesült Államok államainak kódjai nyilvánvalóan nem kereshetőek vissza egyetlen olyan kóddal sem, amely B, E, J, Q, Z, X vagy Y betűkkel kezdődik. Hasonló módon cégek címtárában nem hozhat semmilyen eredményt a U. S. Standard Industry Classification 18-as kódja, mivel ezt a kódot nem adták ki. Az 1400-nál korábbi kiadási évvel rendelkező rekordokra vonatkozó keresés nem hozhat eredményt, kivéve, ha az adatbázisban két számjegyet használnak a kiadási évre vagy hibás adatok vannak ebben a mezőben. A PY>2001 kérdés sem eredményezhet rekordokat, kivéve Books in Printet és néhány más adatbázist, amelyben szerepelnek a jövőben megjelenő könyvek és jövőbeni események. Ha indextételek hosszú listáját nézzük meg annak érdekében, hogy megtaláljuk a szerkezeti ellentmondásokat, ez felszínre hozhat problémákat olyan mezőkben, mint az ISSN, ISBN, körzeti hívószámok és amerikai telefon és faxszámok, amelyeknek rögzített hosszúsága vagy mintája van (vagy mindkettő). Extrém adatok keresése a címjegyzékekben mindig jó módszer arra, hogy pontatlanságokat találjunk. A legnagyobb példányszámú könyvtári folyóiratokra való keresés olyan címeket hív elő, amelyeknek a példányszám-adatai nyilvánvalóan hibásak. Nehéz elhinni például, hogy a megszűnt argentin levéltári folyóirat több mint 700000 példányban jelent volna meg (7.14. ábra), pedig az Ulrich's ezt állítja. Ha úgy lett volna, biztosan nem kellett volna beszüntetni a megjelentetését.

7.14. ábra: Egy argentin levéltári folyóirat valótlanul magas példányszám adatokkal.
Tények nagyarányú és szisztematikus ellenőrzésének másik módja két címjegyzék összehasonlítása, hogy megtudjuk, hogy az eredményeik megegyeznek-e. Jacsó (1991a) 19 referáló és indexelő szolgáltatás feldolgozottságát vizsgálta, ahogy azok az Ulrich'sban és az EBSCO The Serials Directory című adatbázisban szerepeltek, s tízszeres különbségeket talált a két forrás között. Két évvel később Eldredge (1993) végzett hasonló szélesebb alapú összehasonlítást, amelyben szerepelt a National Library of Medicine SERLINE címjegyzéke is, hogy összehasonlítsa a feltárt információ indexelésének pontosságát. Eldredge-nek az a következtetése, hogy "a könyvtárosoknak szkeptikusan kell nézniük ennek a három folyóiratforrásnak az indexelési feltártságra vonatkozó információkat", nagyon mértéktartó. Még ha az adatok csak egyetlen forrásból jönnek is, a téves információk nyilvánvalóak lehetnek.
Az EBSCO-nak semmilyen információja nincs az ISA-ról, sem rövidített, sem teljes formájában. Az Ulrich'sban van információ az ISA referáló és indexelő kiadványról, és azt állítja, hogy 91 folyóiratot dolgoz fel (7.15. ábra). Az ISA folyóiratbázisa csökkent, de nem ennyire. Az ISA dokumentációja azt állítja, hogy több mint 300 folyóiratot referálnak és indexelnek. Egyik adat sem pontos. Több mint 3500 időszaki kiadvány cím van az ISA-ra vonatkozóan a Journal Name Finder Database-ben (benne sok következetlen változattal és elírással), amelyeket valamikor 35 éves történetük során indexeltek és referáltak. Az elmúlt néhány évben a feldolgozott folyóiratok száma körülbelül 230 volt.
A két időszaki kiadványokat feldolgozó címjegyzék közül egyikben sincs információ a Mental Health Abstractsről, és csak az Ulrich's tartalmazott információt a Microcomputer Abstractsről mint referáló és indexelő folyóiratról, az is régi címe, a Microcomputer Index alatt, amely 1994-ig volt érvényes. A cím 2000 elején újra megváltozott, Microcomputer Abstracts helyett Internet & Personal Computing Abstracts lett, de ez nem tükröződik az Ulrich's referáló és indexelő szolgáltatásokat tartalmazó mutatójában, s az EBSCO-t sem ösztönözte arra, hogy szerepeljen referáló és indexelő forrásokat feltáró eszközében. Vajon milyen lehet a minőség-ellenőrzés az időszaki kiadványok címjegyzékeinek aktualizálásakor?

7.15. ábra: Az ISA-ban indexelt folyóiratok száma az Ulrich's szerint.
Hasonlóan árulkodó az a tény, hogy a két kereskedelmi forgalomban elérhető időszaki kiadvány címjegyzék nem tud egyetérteni olyan fontos kérdésekben, mint hogy melyek a lektorált folyóiratok egy adott diszciplínában. A zavar első jele az, hogy a címjegyzékekben feltűnő különbségek vannak a lektorált folyóiratok számában bizonyos szakterületeken. Kisebb különbségek adódhatnak az eltérő osztályozás miatt (például egy lektorált folyóiratot az egyik címjegyzékben a szociológiába, a másikban pedig a pszichológiába sorolhatnak. A különbségek azonban hatalmasak olyan diszciplínákban is, ahol a besorolás egyszerű és egyértelmű lehet, s mindkét címjegyzék azonos vagy majdnem azonos tárgyi fogalmakat használ (7.16. ábra).
Első pillantásra úgy látszik, hogy különbség a lektoráltnak jelzett folyóiratok száma közötti különbség (11407 a The Serials Directoryban és 13124 az Ulrich'sban) összhangban áll a folyóiratok teljes száma közötti különbséggel. Az azonos kategóriákban található számok azonban furcsa különbségeket tárnak fel. Az Ulrich's kétszer annyi lektorált folyóiratot jelez az Oceanography (óceanográfia) és majdnem háromszor annyit Water Resources (vízi erőforrások) kategóriában, mint az EBSCO, míg az utóbbiban az Anthropology (antropológia) területén van 30%-kal több lektorált folyóirat, mint az Ulrich'sban.
Ezeket az adatokat a két CD-ROM-os címjegyzék 1997 őszi kiadása alapján sikerült megállapítani, s a számok folyamatosan változnak. Két évvel később az EBSCO-ban 106 lektorált folyóirat volt (a korábbi 127-ről lecsökkent) a könyvtár- és információtudomány területéről, míg az Ulrich's 194 címet jelentett ilyenként (ennyire nőtt a korábbi 131-ről). A lektorált folyóiratok teljes száma az Ulrich'sban az 1997-es 13124-ről 20000 fölé emelkedett 2000 végére, - ami valószínűtlen növekedés. Hasonló különbségek mutatkoznak a lektorált folyóiratok számában, amikor országok (7.17. ábra) vagy kiadók (7.18. ábra) szerint korlátozzuk őket. Az adatok Ausztriára, Svédországra, Dániára, Norvégiára és Ausztráliára vonatkozóan a legfurcsábbak az országok szerinti összehasonlításban, a kiadók között pedig a John Wiley, Allerton Press és az Elsevier esetében.

7.16. ábra: Jelentős különbségek vannak a lektorált folyóiratok szakterületenkénti számában.

7.17. ábra: Jelentős különbségek vannak a lektorált folyóiratok országonkénti számában.

7.18. ábra: Jelentős különbségek vannak a lektorált folyóiratok kiadónkénti számában.
Még abban az esetben is, ha a két címjegyzék majdnem azonos adatokat mond a lektorált folyóiratok számáról egy adott diszciplínában, az átfedés a kettő között elszomorítóan alacsony, figyelembe véve azt a fontosságot, amit a folyóiratok lektorált státuszához kapcsolnak sokan az egyetemi körökben. A könyvtár- és információtudományi kategóriában például az Ulrich's még mindig nem sorol a lektorált címek közé olyanokat, mint a College & Research Libraries (7.19. ábra), a The American Archivist vagy a Library Resources & Technical Services. Mindkét cég azt állítja, hogy adataikat a kiadóktól nyerik. Valószínűtlen azonban, hogy a kiadók a lektoráltság státuszát különböző módon jelentenék a két kérdőíven.
Jól kell ismerniük a szakterületet ahhoz, hogy észrevegyék egyes címek jelenlétének és mások hiányának abszurditását a lektorált folyóiratok listájáról. Magától értetődően nem lehet lektorált folyóirat a Montana Library Directory és az OCLC Selected Titles, ahogy azt a Serials Directory állítja (7.20. ábra). Hasonló módon megdöbbentő egy könyvtáros számára, hogy az EBSCO nem lektorált periodikaként határozott meg olyan címeket, mint az Information Processing & Management, az Information Services & Use, a Journal of Government Information, a Knowledge Organization és a Serials Review.

7.19. ábra: Lektorált könyvtár- és információtudományi folyóiratok listája az Ulrich's-ban (részlet)
Néha az ilyen listák összehasonlíthatók a legautentikusabb listákkal; azokkal, amelyeket a maguk a kiadók állítanak össze. Az Association for Computing Machinery (ACM) honlapján 16 folyóiratot határozott meg lektoráltként (7.21. ábra). Az Ulrich's ezek közül csak négyet tart lektoráltnak (7.22. ábra). Ez feltétlenül fejlődés ahhoz a két évvel korábbi helyzethez képest, amikor csak egyetlen ACM folyóiratot minősítettek lektoráltnak. A Serials Directory csak nyolc ACM címet határozott meg pontosan lektoráltként, de ugyanakkor két címet tévesen tart annak: a Communication of ACM-et és a Data Base-t (7.23. ábra).

7.20. ábra: Lektorált könyvtár- és információtudományi folyóiratok listája a The Serials Directoryban (részlet)

7.21. ábra: Az ACM lektorált folyóiratai, ahogy azokat az ACM meghatározta.

7.22. ábra: Az ACM lektorált folyóiratai, ahogy azokat az Ulrich's meghatározta.

7.23. ábra: Az ACM lektorált folyóiratai, ahogy azokat a The Serials Directory meghatározta
A két címjegyzéket összehasonlító keresés végrehajtása valószínűleg hasonló különbségeket tárna fel más diszciplínákban is. Az ilyen összehasonlítások fényt derítenek a folyóiratoknak arra a két jellemzőjére is, amelyeket értéknövelt információkként határoz meg a két címjegyzék: a folyóirat példányszámára és az előfizetési árra. Ezeket az információkat feltételezhetően azért gyűjtötték és jelentették, mert a tájékoztatásban, gyűjteményfejlesztésben és bizonyos üzleti döntésekben használják őket, mint például a hirdetési díjak meghatározására.
Nyilvánvaló, hogy az nem szolgálja jól ezeket a célokat, ha jelentős eltérések vannak a két címjegyzék között. A különbségek magukért beszélnek. Egyeseket könnyű ellenőrizni a nyomtatott időszaki kiadványban szereplő vagy a kiadók katalógusaiban hozzáférhetővé tett információk alapján. Az ilyen összehasonlítás kiterjeszthető más adatelemekre is, de feltehetően ezek a legfontosabbak.
Időnként az adatbázisok kiadói okozzák az adatbázisok pontatlanságait. Ez az oka az egyik legfurcsább, legnagyobb mértékű hibának, amellyel az Ulrich's DIALOG-os változatában találkozhatunk. Ha az Excerpta Medica (az egyik legnagyobb referáló és indexelő vállalkozás) kezdetű folyóiratcímeket keressük, 49 folyóiratot találunk, mint például az Excerpta Medica, Section 16: Cancer. Az Excerpta Medica által indexelt és referált folyóiratokra vonatkozó keresés azonban nulla találatot ad (7.24. ábra). Az input feldolgozásakor az adatbázis tervezője minden bizonnyal tévesen, az Exerta Medicaként elírt formában adta meg az eredeti kód (mondjuk EXM) feloldását. Ezért van az, hogy 5654 rekord van az elírt névalak alatt (7.25. ábra). Az Ulrich's Ovidos változata 5630 rekordban helyesen határozza meg a referáló és indexelő szolgáltatás nevét (7.26. ábra).
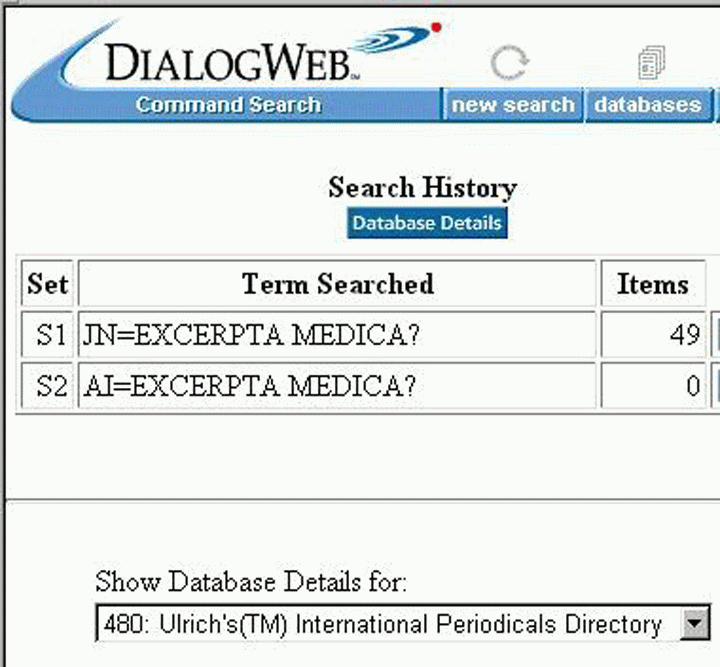
7.24. ábra: Olyan folyóiratok keresése, amelyeket az Excerpta Medica referál és indexel a DIALOG-nál.

7.25. ábra: Referáló és indexelő szolgáltatás hibásan kódolt neve az Ulrich's DIALOG-os változatában.

7.26. ábra: Pontosan kódolt Excerpta Medica az Ulrich's Ovidos változatában.
Az adatbázisok címjegyzékeiben egyes pontatlanságok azonnal nyilvánvalóvá válnak a gyakorló szakember számára, ilyen a Social SciSearch adatbázis rekordja a World Databases címjegyzékben. Ha valóban minden héten 780000 rekorddal frissítenék, mérete 15 hét alatt megduplázódna. Ilyen fajta hiba rengeteg van a kivételesen silány World Databases címjegyzékben.
A kevésbé tapasztalt használók számára is egyszerűen megállapíthatóak a pontatlanságok, amikor olyan alapvető információkat hasonlítanak össze a két adatbázisban, mint az adatbázis mérete, az aktualizálás gyakorisága, az aktualizálás mérete, az óradíj, a nyomtatás ára vagy az adatbázis licenc díja (7.27. ábra).

7.27. ábra: Nyilvánvaló pontatlanság a G. K. Saur World Databases adatbázisában.
Néha nem lehet a címjegyzék kiadóját hibáztatni a pontatlanságok miatt, mivel azok a primér forrásokból származnak. Ez okozott némi problémát a könyvtárosoknak, amikor a Sage Publications a Journal of Contemporary Ethnography 1999 februári számát a kötet első számaként határozta meg, pedig maga a folyóirat azt állítja, hogy áprilisban, júliusban, októberben és januárban jelennek meg (7.28. ábra). Ez csak kiegészítette azt a zavart, amit a Sage-nek az a terve okozott, hogy évente hat számot ad ki, de mivel ennek a megjelenési gyakoriságnak az elhatározása nem végleges, a könyvtárakat nem tájékoztatták róla (7.29. ábra).
Tárgy: Journal of Contemporary Ethnography
Nincs jó napom.
Ennek a lapnak a februári száma egy volt a problémák halmazában, egy üzenettel egy hallgatómtól, hogy a hónap megjelölése nem felel meg a szokásos megjelenési időnek. Így hát megnéztem belül, s azt találtam: "Megjelenik évente négyszer - áprilisban, júliusban, októberben és januárban."
Mit csinálnak ezzel a többiek, s ha nem verem tovább a fejem a falba, elmúlik a fájdalom?

7.28. ábra: E-mail a zavaró kronológiai jelzéssel kapcsolatban.
Tárgy: Re: Journal of Contemporary Ethnography
Felhívtam a Sage Publicationst, s azt mondták nekem, hogy a "Journal of Contemporary Ethnography" 1999-től kéthavi folyóirat lett. Így a februári szám az első ebben az évben. Azonban amikor megkérdeztem, hogy a Sage kiküldene-e levelet, informálva előfizetőit erről a változásról, az operátor nem tudta. Miközben segített nekem, hallottam mormogását, hogy a Sage számítógépeit nem aktualizálták teljesen, hogy az új hónapokat megmutathassa. Remélem, hogy ez segíteni fog. Kérlek, ne verd tovább a falba a fejed. Helyette írd fel a különböző kiadók nevét egy céltáblára, amelyek ilyet csinálnak, s azután lődd ki nyilaidat.

7.29. ábra: E-mail a Sage hibás információiról egyik kiadványuk megjelenési gyakoriságával kapcsolatban.
A könyvtárosok és az információs szakemberek érzik annak a terhét, hogy felelősek az ügyfeleik számára adott információkért. Felelőtlenség hivatkozni akár az Ulrich's International Periodicals Directory, akár a Serials Directory adatára egy folyóirat lektoráltsági státuszával kapcsolatban egy egyetemi pozícióról folyó vitában. Törlési döntések meghozása a két adatbázis által nyújtott információk alapján arról, hogy melyik referáló és indexelő folyóirat tartalmaz meghatározott periodikumokat, hasonló felelőtlenség. Ha nem lehet megtalálni egy adatbázisban egy állásra jelentkező írásait amiatt, mert nevét gyakrabban írják ott hibásan, mint helyesen, eldöntheti, hogy felveszi-e vagy sem. Nyilvánvalóan hibás adatok szolgáltatása adatbázisok ezreiről a World Databases ügyfelei számára hasonló az orvosi műhibához. Ilyen adatokért rendkívül magas árakat fizettetni erkölcstelen dolog.
Sok olyan könyvtáros van, aki erőteljesen kritizálja az ingyenes webes adatbázisokat hiányosságaik miatt. Igazuk van abban, hogy ezt teszik, de tudniuk kell, hogy a nagyhírű hagyományos információszolgáltatók előkelő székházaikból gyakran sokkal hibásabb adatbázisokat szolgáltatnak csinos kis summáért. Pontos információkat tartalmazó adatbázisok összeállítása sokba kerül, ennek az árát kevés tartalomszolgáltató akarja megfizetni.
Az H. W. Wilson azon ritka cégek közé tartozik az információiparban, amelyek különösen kényesek arra, hogy ellenőrizzék információikat és visszamenőlegesen is korrigálják a téves adatokat, ha a hibákra vagy változásokra rájönnek. Ez biztosan sokkal többe kerül, mint PR szakembereket vagy dumamatyikat alkalmazni, akik hamis portékát árulnak, kifogásokat és magyarázatokat találnak adatbázisaik sok hiányosságára.
Ezek a praktikák nem segítenek azoknak a könyvtárosoknak, akik néha maguk is végfelhasználók, vagy pedig közvetlenül szembe kell nézniük a végfelhasználókkal. Drága adatbázisok nagyfokú és súlyos pontatlanságai a könyvtáros legnagyobb ellenségei közé tartoznak. Először meg kell találni ezeket, majd a szolgáltatókat szembesíteni kell velük.


