
8. A formátum és a tartalom következetessége
Egy tökéletes világban szinte minden adatelemet úgy vinnének be egy adatbázisba, hogy kontrollált szótárt vagy valamilyen szabványosított név - vagy rövidítés - listát használnak. Még akkor is lennének különbségek az adatbázisok között a személyek és cégek neveiben, a folyóiratok címének vagy a deszkriptoroknak a formájában, de legalább egy adatbázison belül a szavak helyesírása, a folyóiratcímek és a cégnevek rövidítései megjósolhatóak lennének. Cserében ez megkönnyítené a használóknak azt, hogy megtaláljanak minden olyan cikket, amelyet egy adott folyóiratból származik, minden hivatkozást, amely egy cégre vonatkozik, és a hírekbe a legkülönbözőbben transzliterált formában bekerülő híres vagy hírhedt személyek minden említését. Gondoljunk csak Líbia vezetője, Thaiföld miniszterelnöke vagy Észak-Korea fővárosa nevének változataira.
Ezeknek a változatoknak némelyike a transzliterációs szabályok változásainak köszönhető. Ezek kereszthivatkozások segítségével megtalálhatóak egy böngészhető listában. Az ilyen megoldások valóban jól működnek az H. W. Wilson adatbáziscsalád CD-ROM-os változataiban vagy a PAIS-ban, s kisebb mértékben az EBSCO adatbázisaiban. Az online világban azonban általában nincsenek kereszthivatkozások egy név egyik formájáról a másikra - azon néhány adatbázis deszkriptorainak kivételével, amelyeknek van online tezaurusza. (Az indexelés minőségét, benne az indexelés következetességét a 10. fejezetben tárgyaljuk. A folyóiratok és más dokumentumtípusok feldolgozásának következetességét az 5., a feltárt forrásokkal foglalkozó fejezetben tárgyaljuk.
A következetesség megvalósítása különösen szükséges olyan adatbázisokban, amelyek sok különböző forrásdokumentumot használnak, s amelyeknek gyakran megvannak a maguk házi szabványai. Feltételezhető, hogy a Washington Postnak van ilyen szabványa; ezért egyetlen online fájlon belül az országok, személyek, mozgalmak és cégek neve következetes formában jelenik meg. Azonban azok, akik több indexelő, referáló és teljes szövegű adatbázist készítenek (mint például a Gale Group, Bell Howell és EBSCO), szabványosítaniuk kell ezeket a neveket, s ez alapján következetesen alkalmazniuk az újságok, folyóiratok és magazinok ezreiből alkotott rekordokhoz. Sok adatfájl előállítónak megvan papíron a maga egységesített névalak listája, de az adatok bevitelekor láthatólag nem vetik össze a tételeket ezekkel a listákkal.
Az H. W. Wilson cég egyike annak a kevés tartalomszolgáltatónak, amely elérte a következetesség szinte kifogástalan szintjét. Érdekes módon egy ingyenes, weben született adatbázis, az Internet Movie Database egy másik teljesen tiszta és következetes forrás, amely szintén szolgáltat kereszthivatkozásokat a címváltozatokból és a művészi álnevekből. Ezt olyan módon teszik, amit tanítani kellene a legjobb iskolákban is.
Az elírásokhoz és az egyéb pontatlan adatelemekhez hasonlóan, a következetlenség is azt okozhatja, hogy igazán releváns tételeket vesztünk el egy adatbázisban történő keresés során. Azok a használók, akik defenzív keresési stratégiákat alkalmaznak, minimalizálhatják a következetlenség hatását, de sok idő kell a különböző változatok böngészéséhez és kereséséhez, ez pedig pénzbe kerül, különösen olyan rendszerekben, amelyek díjainak még mindig jelentős részét képezi a kapcsolati idő. Sok információkereső rendszer nem nyújt megfelelő böngészési lehetőséget, amely pedig csökkenteni tudná a következetlenség néhány problémáját.
Mezőspecifikus indexek (szerzői index, kiadói index, folyóiratcím index) böngészése és a bennük való keresés fényt derít a következetlenségekre. Azok a rendszerek, amelyek csak nagy, mindent együtt tartalmazó indexet szolgáltatnak a böngészéshez, mint a SilverPlatter DOS-os változata, elrejtik a következetlenségeket. Nem nyújt segítséget az, ha olyan indextételeink vannak, amelyeket számos mezőből generálnak anélkül, hogy lennének megkülönböztető prefixeik (előtagjaik), amelyek meghatároznák, hogy a tételt melyik adatelemből vették. Nem segít, ha nem böngészhetünk a nyelv, dokumentumtípus vagy a kiadás országa mezőjében.
Például a Sociological Abstractsben a román nyelv Romanian formában szerepel (8.1a. ábra), míg a kiadás országa Rumania (8.1b. ábra), az országra vonatkozó deszkriptor pedig Romania (1985-től) és Rumania (1984-ig) formában. Egyik sem pontatlan, de a tételek kétségtelenül következetlenek, és a SilverPlatter DOS-os változatában soha nem szerzünk tudomást róluk. Szerencsére az adatbázisok DIALOG-os változatában (és sok másikban is) a nyelvek és az országok indexe böngészhető. Néhány online tezaurusz is böngészhető, hogy megtaláljuk a kívánt tárgyi kifejezéseket és a szélesebb, szűkebb és kapcsolódó kifejezéseket (8.1c. ábra).
8.1a. ábra: A nyelvi index kifejezései a Sociological Abstractsben.
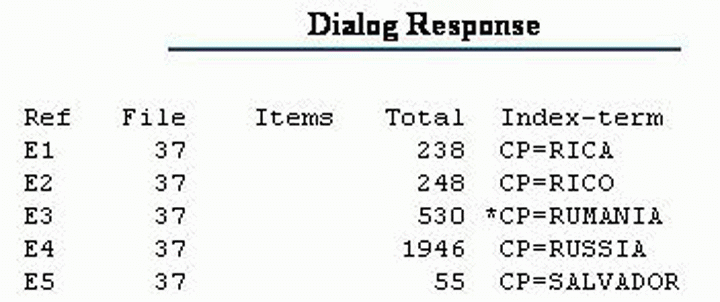
8.1b. ábra: A kiadás országa indexkifejezései a Sociological Abstractsben

8.1c. ábra: Deszkriptorok a Sociological Abstracts tezauruszában.
Bár a DIALOG sok mezőspecifikus böngészhető indexet ajánl, nincs külön böngészhető deszkriptor index, például DE=, amely segítene a használóknak, hogy kiválasszák a legmegfelelőbb fogalmakat (különösen akkor, ha a tezaurusz online változatát nem készítették el, hogy útmutatást adhasson), és megismerjék a pontatlanságokat és következetlenségeket. Másik oldalról az Ovid minden lehetséges indexelt adatelemet böngészhetővé tesz, s egyedi módon, lehetővé teszi a használóknak, hogy használat közben kombinált ad-hoc indexeket alkossanak. Például a Sociological Abstracts Ovid-os változatában a használó létrehozhatja a nyelv, a kiadás országa és a deszkriptorok kombinált indexét. Az eredmények listájában a nyelv, a kiadás országa és a deszkriptor mező különböző kifejezései egy közös fájlba kerülnek.
Minden adatbázis szerzői indexének böngészésekor megérezhetjük a következetlenség szintjét. Az elírások és a következetlenül írt formák gyakran egymáshoz közel találhatók. A Bowker cég Ulrich's adatbázisában számos következetlen formát használ a saját nevére (8.2. ábra). Ezek közül egyesek szabályosak, de sok csak a testületi nevek egységesített fájljának - és némi odafigyelésnek - a hiányát mutatja. Megjegyzendő, hogy sok további változat volt évekkel ezelőtt (mint például R. R. Bowker, RR Bowker és R R Bowker), amelyeket nagyrészt megszüntettek.

8.2. ábra: A Bowker név variációinak tömege egy Bowker adatbázisban.
Amikor a következetlen tételek nincsenek egymáshoz közel, a használó elvesztheti a rekordok többségét, amelyek tartalmazzák azt a nevet, amelyikre keresett. Amikor egy használó megtalálja a John Wiley & Sons, Inc. alakot az Ulrich's kiadói indexében (8.3. ábra), jó esélye van annak, hogy nem fogja megpróbálni a Wiley formával kezdődő részben is ellenőrizni, azaz olyan rekordok százait veszti el, amelyek eme konglomerátum brit, ausztrál és amerikai részlegének valamelyik névváltozata alatt jelennek meg (8.4. ábra).
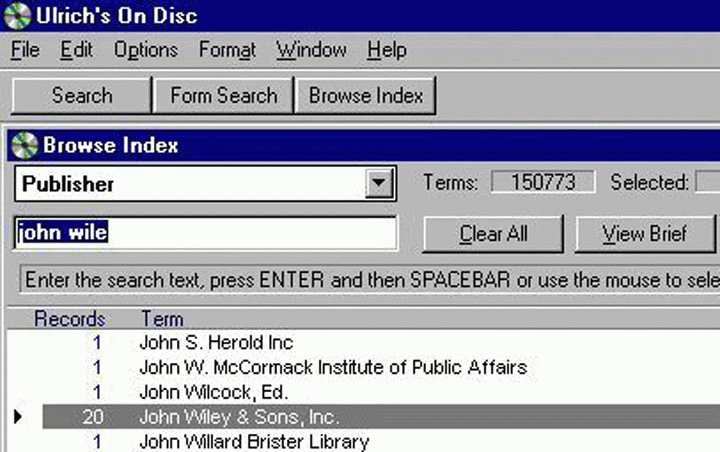
8.3. ábra: Tételek az Ulrich'sban a John Wiley & Sons, Inc. név alatt.

8.4. ábra: További tételek százai az Ulrich'sban a Wiley & Sons, Inc. név alatt.
A folyóiratcím mező elszórt tételeinek keresését nagyban megkönnyítette a DIALOG a Journal Name Finder adatbázissal, amely mind szavanként, mind kifejezésként indexelt tételeket alkot az adatbázisok folyóiratcím mezőiből. A hozzáértő keresők alkalmazhatnak olyan keresést, mint SELECT news AND world AND report, hogy megtalálják a népszerű magazin címének (U. S. News & World Report) variációit a különböző adatbázisokban. Lehangoló, hogy egyedül az ERIC adatbázis három különböző formát használ az ebből a hetilapból felvett 37 cikkhez. Más adatbázisoknak szintén megvannak a maguk variációi, mint például a Transportation Information Services adatbázisnak (File 63 a DIALOG-nál) (8.5. ábra).
A következetlenségek abból is származhatnak, hogy a különböző primer forrásoknak eltérő a gyakorlatuk - például a szerzők második vagy harmadik keresztnevének rövidítésére. Maguk a szerzők is következetlenül használhatták őket a különböző publikációkban. Az H. W. Wilson cég egységesített névalak fájljának szépsége az, hogy egy tétel alatt összehozzák egy szerző műveit még akkor is, ha a primer források nem írják nevüket következetesen vagy pontosan.
A probléma mérésének egy viszonylag szisztematikus módja az, ha böngészünk a szerzők nevének indexében, és olyan előtaggal rendelkező holland vagy német családneveket keresünk, mint például Van Brakel vagy Von Seggern, azután megpróbáljuk megtalálni az olyan változatokat, amelyek az előtagból utótagot csinálnak. Egy gyors ellenőrzés sokat elmond arról, hogy a fájl előállítója milyen következetesen kezeli a személyneveket.

8.5. ábra: A U. S. News & World Report címének különböző formái.
Nagyon lehangoló, hogy a LISA adatbázisban olyan sok különbözően írt változat van a személynevekre. Vegyük például Pieter van Brakelt, aki a V betű alatt 41 tételben szerepel négy különböző módon írt változatban, s a B betű alatt is 30-szor három változatban (8.6. ábra). Az ISA-ban a név 31 tételben található meg két formában s csak egyszer a B betű alatt. A LibLitben - nem meglepő módon - Pieter van Brakel mind az 58 rekordja a B betű alatt található egyetlen formában. Hasonló eredményre jutunk sok más tesztkeresés során is.
A Getty egységesített névalak fájlja (Getty Name Authority File) megmutatja, hogy a különböző források sajátos formái hogyan kezelhetők egy kontrollált szótár segítségével, kereszthivatkozásokkal a különböző névalakoktól a Getty adatbázisok által választott, szabványosított formához (8.7. ábra).

8.6. ábra: Súlyos következetlenség a LISA szerzői indexében.

8.7. ábra: Részlet a példás Getty Name Authority File-ból.
A folyóiratcímeket még a szerzői neveknél is következetlenebbül alkalmazzák a változatok sokféle lehetősége miatt. Ezek a következők: a kiadó testületek rövidítéseinek és teljesen kiírt változatainak használata, a címben szereplő szavak közül soknak a rövidítése, az alcímek ötletszerű felvétele és kihagyása, az and és and of következetlen kihagyása, helyettesítésük az & és a kötőjel (-) karakterekkel, nem említve a kiadás helyével való kiegészítést, hogy megkülönböztessék egymástól az egyébként teljesen azonos folyóiratcímeket. A Database látszólag teljesen egyszerű címe nagyon sok változatban található meg ugyanazon az adatbázison, a PASCAL-on belül (8.8. ábra). Nincs olyan adatbázis, amely a folyóiratcímek mezőjének következetlenségeiben és pontatlanságaiban vetekedhetne a PASCAL adatbázissal, amelyet a Francia Tudományos Kutatási Központ ad ki. A könyv szerzőjének becslése szerint átlagosan 4,3 címvariáció és elírás jut egy tételre (nem számítva a szabályos rövidítéseket). Ez az arány úgy érhető el, hogy a hosszabb címekre variációk tucatjai vannak, ahogyan azt a Bulletin of the American Society for Information Science (8.9. ábra) és a Journal of the American Oil Chemists' Society (8.10a. és 8.10b. ábra) példája illusztrálja. Az első példában a legtöbb tétel elég közel van egymáshoz, de a második cím esetében a tételek nagy mértékben szóródnak. Csak azért soroljuk fel itt őket egymás után folyamatosan, hogy a listát ennek a könyvnek egy oldalára korlátozzuk. (Még szerencse, hogy az oil szó nem rövidíthető, s így nem alkottak még további tucatnyi vagy még több variációt.)

8.8. ábra: A Database folyóirat címének változatai egyetlen adatbázisban, a PASCAL-ban.

8.9. ábra: Egy hosszabb folyóiratcím változatai a PASCAL-ban (egymáshoz közeli tételek)

8.10a. ábra: Egy hosszabb folyóiratcím változatai a PASCAL-ban (szétszóródott tételek).

8.10b. ábra: Egy hosszabb folyóiratcím változatai a PASCAL-ban [folytatás]
Még egy kisebb adatbázisban is, amely a PASCAL-nál sokkal kevesebb folyóiratot tartalmaz, könnyen megtörténhet, hogy a szóródás miatt a használók nem találnak meg különböző módon írt folyóiratcímeket és így fogalmuk sincs az ebből a folyóiratból származó olyan rekordok nagy százalékáról, ahol épp ezt a formát használják. Például az ISA-ban szerepel a MIS Quarterly és a Management Information Systems Quarterly folyóiratcím is (8.11. ábra). Az általánosabban használt névalakhoz sokkal kevesebb rekord tartozik, mint ahhoz a névhez, amit sokkal kisebb valószínűséggel keressük, s amelyet a legtöbb másik adatbázisban csak ritkán használnak.

8.11. ábra: A találatok számának megoszlása egy folyóirat címének két egymáshoz nem közeli formája között.
A következetlenségek olyan látszólag egyszerű mezőkben is megmutatkozhatnak, mint a dokumentumtípus. A Periodical Abstracts Plus Text nem az egyetlen adatbázis, amely különböző dokumentumtípusként határozta meg ugyanannak a rovatnak ("Péter's Picks and Pans") az egyes részeit, ahogy azt a 8.12. ábra mutatja.

8.12. ábra: Következetlenül meghatározott dokumentumtípusok ugyanannak a rovatnak a közleményeiben.


