
9. Teljesség
A következetlenségek az adatbázisokban problémát jelenthetnek a keresők számára. A pontatlanságok komoly következményekkel járhatnak. A teljesség hiánya azonban végzetes lehet egy keresésnél. A következetlenségek és pontatlanságok láthatók. Az adatbázis nem teljes volta, tehát amikor egy vagy több, a keresésnél szokásosan szűrésre használt adatelem a rekordok nagy számából hiányzik, magától értetődően nem látható. Néha a súgó (help file) figyelmezteti a használót a teljesség hiányára; néha a hozzáértő használó képes felderíteni egy adatbázis teljességének hiányát, de gyakran senki nem tud erről. Az elkövetett hibák szabad szemmel is láthatóak, a mulasztásból eredő hibák nyilvánvalóan nem. Azonban drasztikusan torzíthatják az eredményeket, anélkül, hogy a használó tudatában lenne ennek.
Súlyos következményeik ellenére a mulasztásokból eredő hibákat (kihagyásokat) nem tárgyalták olyan mértékben, mint az elkövetett hibákat. Basch (1990a) állapítja meg, hogy a kihagyások vagy az üresen hagyott mezők gyakran eredményezik azt, hogy a kereső nem jut hozzá releváns rekordokhoz. Quint (1989) állítása szerint félrevezető és drága outputot eredményez, amikor az eredményeket olyan adatelemek szerint rendezik sorba, amelyek nincsenek jelen minden rekordban. Ez még kevésbé lehet nyilvánvaló a használók számára, akik nem jönnek rá, hogy a kiadási év szerint való rendezés egyszerűen kirostálja azokat a rekordokat, amelyekben nem található érték a kiadási év mezőjében. Tenopir (1992, 1995) ismételten figyelmeztetett a hiányzó adatelemek veszélyeire. Jacsó (1993b) számos nagynevű adatbázisban mutatja ki a teljesség hiányának mértékét, továbbá azokat a módszereket, amelyekkel a kihagyás mérete vizsgálható.
A problémát súlyosbította az elektronikus adatbázisoknak a nyomtatott megfelelőikhez képest meglevő, széles körben hangoztatott előnye; vagyis az, hogy sok olyan adatelem szerint is kereshetőek, amelyek szerint ezt a nyomtatott változatokban nem lehet megtenni. Ez igaz, de az is igaz, hogy a nagyméretű kihagyás esetén a keresés nem vezet eredményre. Például az időszaki kiadványok kereshetők az Ulrich's Plus adatbázisban a Kongresszusi Könyvtár osztályozási jelzete szerint. Ezt büszkén sorolják fel a hozzáférési pontok között a Bowker termék katalógusában, s a keresési űrlapon is előkelő helyen jelenítették meg. Amit a naiv használó nem tudhat, az az, hogy a 226276 rekord közül csak 43118-ban (19%) van meg ez a kód (9.1. ábra). Ezt nem lenne szabad hozzáférési pontként felajánlani, mivel ennek használata automatikusan az adatbázis ötödére korlátozza a keresést.
Amikor ezt a nagyon jelentős mértékű kihagyást a könyv szerzője egy konferencián tartott előadásán közzétette, a Bowker akkori képviselője azzal érvelt, hogy kevés használó keresne a kongresszusi könyvtár osztályozási jelzete szerint vagy használná azt szűrőként. Ez az érvelés azonban sántít. Minden egyetemi könyvtár és sok szakkönyvtár a Kongresszusi Könyvtár osztályozási jelzetét használja a Dewey-jelzet helyett (amely egyébként minden rekordban elérhető). Sokkal jobb lenne előzékenyen és egyértelműen jelezni a kereső képernyőn vagy legalább a súgóban, hogy a rekordoknak csupán 19%-ában található meg ez a jelzet. Az adatbázis Bowker által kiadott CD-ROM-os változatában legalább felfedezhető a kihagyás mértéke egy kereséssel, ahogy azt a 9.1. ábra mutatja.
Azokban a változatokban azonban, amelyek a két osztályozási jelzetet ugyanabba a mezőbe rakják vagy nem engedik meg a prefixes indexekben a teljes csonkolással való keresést, ez a hiányosság rejtve marad. A Kongresszusi Könyvtár osztályozási jelzetével végzett keresések eredményei durván félrevezetik a használót. A DIALOG-os változatban a Kongresszusi Könyvtár és a Dewey-féle osztályozás jelzeteit egy indexben olvasztották össze, így még a hozzáértő használó sem képes arra, hogy kitalálja, milyen elfogadhatatlanul hiányosak a rekordok.
Az ár és a példányszám adatai hiányának mértéke az Ulrich'sban is figyelmeztető jel, hogy ne keressünk ezen adatelemek szerint még akkor sem, ha erre csábítanak minket a Bowker reklámanyagai. Az ár szerint nem lehet keresni a DIALOG-os változatban. Bár a kiadó mezője "csak" kevesebb mint 10000 rekordból hiányzik, ez furcsa, mert a feltételezések szerint az adatokat a folyóiratok kiadói szolgáltatják, így ennek az adatelemnek igazán elérhetőnek kellene lennie.
9.1. ábra: A Kongresszusi Könyvtár osztályozási jelzeteinek
nagymértékű kihagyása az Ulrich's Plus adatbázisban.
A legtöbb adatbázis kihagy természetesnek tekintett adatelemeket, bár csak kevesen olyan mértékben, mint amit itt bemutattunk. Azonban még így is riasztó látni, hogy az adatbázis kiadója nem figyelmeztet arra, hogy az ERIC adatbázis rekordjainak 28%-ában nincs dokumentumtípus mező; ez a Compendexben 32%, az NTIS-ben 72% (9.2. ábra), a Packaging Science and Technologyban 78% és a GeoArchive-ban 90% (9.3. ábra). Még az adatelemek látszólag kismértékű kihagyása is nagyon jelentős lehet a legnagyobb adatbázisok esetében. Az AGRICOLA-ban a rekordok 5%-ában nincs nyelvi mező, ami nem hangzik rosszul, amíg rá nem jövünk, hogy egy 4 millió rekordos adatbázisról van szó, így a kihagyások csaknem 200000 rekordot zárnak ki, amikor valaki nyelv szerinti szűrést csinál.

9.2. ábra: A dokumentumtípus mező kihagyása az NTIS adatbázisból minden magyarázat nélkül.

9.3. ábra: A dokumentumtípus mező kihagyása a GeoArchive adatbázisból minden magyarázat nélkül.
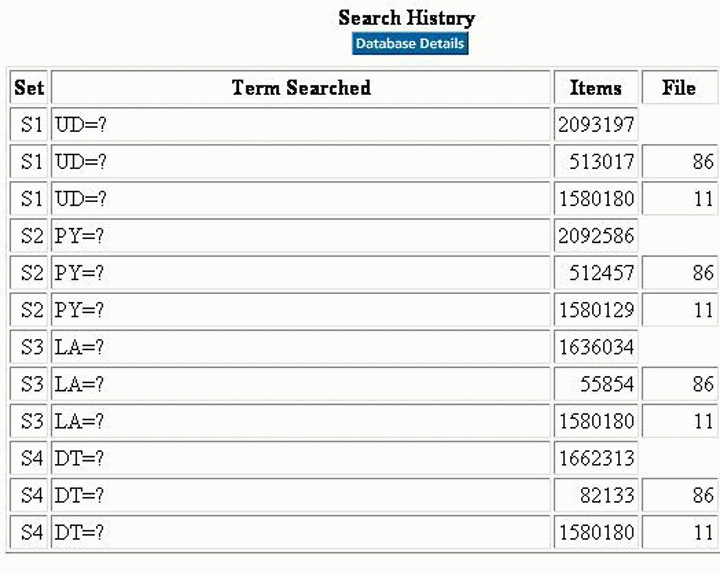
A három könyvtár- és információtudományi adatbázis (9.4. ábra) elég jó teljesítményt nyújt olyan gyakran használt keresési kritériumok körében, mint a kiadási év, nyelv és dokumentumtípus. (A LISA nem ígér dokumentumtípust, így a nulla találat elfogadható, bár ez elég kiábrándító tervezésre utal.) Ahogyan a 9.5. ábra adatai mutatják, a PsycINFO szintén jól teljesített, de a Mental Health Abstractsben 513017 rekord közül csak 82133-ban van dokumentumtípus (16%). A nyelvi mező ugyancsak hiányzik ezen adatbázis rekordjainak csaknem 90%-ából, de ez érthető, ha tudjuk, hogy házi gyakorlatuk szerint az angolt mint nyelvet nem kapcsolják a rekordokhoz. Más kérdés az, hogy az MHA DIALOG-os adatbázis-leírása az LA=ENGLISH formát használja keresési példaként (9.6. ábra), ami - nem meglepő módon - nulla rekordot eredményez (9.7. ábra). Bár együtt érezhetünk a fájl előállítójával, aki olyan szívósan küzdött ennek a szónak a helyes írásmódjával (9.8. ábra), a használókat figyelmeztetni kellene arra a gyakorlatra, hogy a sok próbálkozás után abbahagyták az angolnak a rekordokhoz nyelvként való hozzákapcsolását.

9.4. ábra: A mezők jelenlétének ellenőrzése a könyvtár- és információtudományi adatbázisokban.
9.5. ábra: A mezők jelenlétének ellenőrzése a PsycINFO és az MHA adatbázisokban.

9.6. ábra: Részlet az MHA adatbázis-leírásából.

9.7. ábra: Nincs rekord az English szóra az MHA nyelvi mezőjében.
A PsycINFO a legjobb minőségű adatbázisok közé tartozik, és nem meglepetés, hogy Ovidos változatában végzett tesztkeresés (9.9. ábra) azt mutatja, hogy mind az 1594013 rekordban volt dokumentumtípus mező. A populáció mezőjét szintén úgy alkalmazták, hogy vagy a human (emberre vonatkozó), vagy az animal (állatokra vonatkozó) fogalom szerepeljen benne, de egy friss teszt azt tárta fel, hogy a rekordok 20%-ában nincs meg ez az adatelem.

9.8. ábra: Részlet az MHA adatbázis nyelvi indexéből.

9.9. ábra: A rekordok teljes számának és két mező jelenlétének meghatározása az Ovidban.
A kihagyást a következetlenség speciális fajtájaként is meg lehetne határozni. Ám az alapvető adatelemek, mint például a nyelv, ország, kiadási év, illetve a dokumentum típusa megadásában megnyilvánuló következetlenség olyan következményekkel jár, amely külön megközelítést igényel. Meg kell jegyezni, hogy nem minden adatelem esetében várható el, hogy minden rekordban jelen legyen. Nyilvánvaló, hogy a szerzői nevet nem lehet megadni anonim közlemények esetén. Nem minden időszaki kiadványnak van ISSN száma, s nem mindegyik határozza meg a szerkesztőt adatelemként - ahogy például az Ulrich'sban sem.
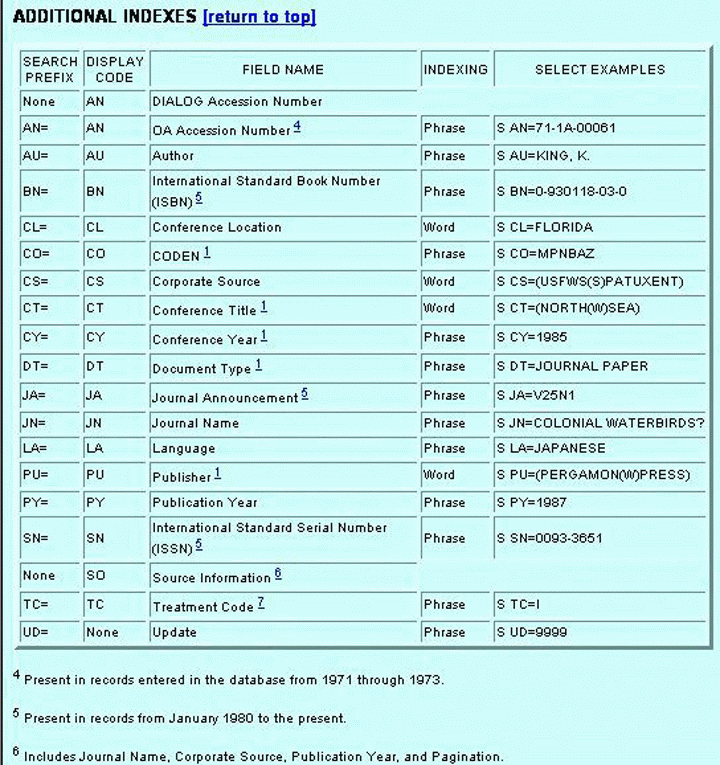
Minden kiadványhoz tartoznia kell azonban nyelvnek és a dokumentumtípusnak. Gyakori eset, hogy az ilyen adatelemeket nem használták az adatbázis korai éveiben, később vezették csak be őket. Erre a tényre a használót figyelmeztetni kellene. Az ABC-Clio így tesz az America History & Life és a Historical Abstracts adatbázisok esetében, és felhívja a figyelmet arra, hogy a nyelvi mezőt csak 1980-tól adták meg az adatbázisokhoz (míg az adatbázisok 1963-ig, illetve 1973-ig mennek vissza).
Így tesz az Oceanic Abstracts is (9.10. ábra), megjegyezve, hogy a dokumentumtípust csak 1971 és 1973 között használták, ami megmagyarázza, hogy miért csak a rekordok 8%-ában található meg a dokumentumtípus mező. A Searchable Physics Information Notices (SPIN) adatbázis a használó tudomására hozza, hogy a dokumentumtípust csak akkor kapcsolták a rekordhoz, ha az nem folyóiratcikk volt. Néha az okot ki tudják következtetni a tapasztalt használók. Az Occupational Health and Safety adatbázisban is csak a rekordok 8%-ában van nyelvi mező. A nyelvi indexre való pillantás azonban indirekt módon magyarázattal szolgál: nincs angol nyelvű tétel, így nyilvánvalóan a feltételezett érték.
A Books in Printben az angol nyelvű dokumentumok képtelenül kis eredményhalmaza sejtetheti meg a gyakorlott keresővel, hogy csak a két- és többnyelvű dokumentumok (például szótárak) esetében határozzák meg az angol nyelvet.
Egyes esetekben figyelmeztetnek egy adatelem nagymértékű kihagyására, de másikra nem. Az ERIC-ben nincs figyelmeztetés arra, hogy a dokumentumtípus mezőt a rekordok 28%-ában kihagyták, de van egy megjegyzés arról, hogy a nyelvet csak 1979-től adták meg. Ugyanez érvényes az NTIS-re is (9.11. ábra). A BIOSIS figyelmeztet arra, hogy a nyelvet csak 1978-tól adják hozzá a rekordokhoz, de nincs figyelmeztetés vagy magyarázat arra, hogy miért nincs a rekordok 65%-ában dokumentumtípus mező. Egy 12 millió rekordos adatbázis estében a kihagyásnak ez az aránya gigantikus.
9.10. ábra: Az Oceanic Abstracts adatbázis-leírásának információi.

9.11. ábra: Hiányzik a dokumentumtípus mező
nagy mértékű kihagyására vonatkozó megjegyzés az NTIS-ben.
Az, ha nem figyelmeztetik a használókat az ilyen kihagyásra, olyan, mint amikor egy étterem vezetője nem ad vészjelzést, amikor a konyha lángra kap, mert arra van csak gondja, hogy minden vendég kifizesse a számlát, mielőtt elmenekül a vendéglőből. A keresők megégethetik ujjukat, ha nem figyelnek arra a súlyos fogyatékosságra, hogy a rekordok hiányosak. Az a hatékony eszköz, amellyel a keresés eredményét nyelv, dokumentumtípus és osztályozási jelzetek szerint szűrhetjük, könnyen veszélyes eszközzé válhat.
Nagyon kevés olyan adatbázis van, amely legalább világossá teszi az adatelemek kihagyását a keresési folyamat során. A Multimedia and CD-ROM Directory például világosan megmutatja, hogy hány rekordban nincs az árra vonatkozó információ (9.12. ábra).

9.12. ábra: A hiányzó adatelemek egyértelmű meghatározása.
A Directory of Library and Information Professionals, amely ugyanazt a szoftvert használja, nem használja ki ugyanezt a technikát arra, hogy figyelmeztesse a használót arra, hogy a keresésre felkínált adatelemeknek csak egy nagyon kis része található meg valóban a rekordokban. Az egyetlen kivétel az információs szakemberek neme, mivel a nyomtatott dokumentáció figyelmezteti rá a használót, hogy a rekordoknak csak kevesebb mint a felében van a nemre vonatkozó információ. (Az más kérdés, hogy hány használó fér hozzá a nyomtatott dokumentációhoz és/vagy akarná elolvasni azt.)
A legkönnyebb mód arra, hogy megismerjük az adatelemek kihagyásának mértékét az, amikor az adatbázis magától megadja ezt az információt, ahogy azt a 9.12. ábra mutatja. A hiányosságok megvizsgálásának másik módja az, hogy megnézzük az olyan indextételeket egy referáló és indexelő adatbázisban, mint a N/A, Not Available (nem elérhető) vagy Undetermined (Meghatározatlan). Nem csak rendkívül magasnak, de furcsának is tűnik, hogy a Library Literature-ben 25880 olyan rekord van, amelyben a nyelv meghatározatlan, amíg nem végzünk némi kutatást s rá nem jövünk, hogy az H. W. Wilson cég gyakorlata szerint a könyvkritikákat tartalmazó rekordoknál nem adják meg a nyelvet (9.13. ábra). Ez nem logikus, és a kritikából a kritizált mű nyelve biztosan meghatározható lenne.

9.13. ábra: Rekordok meghatározatlan nyelvvel a LibLit-ben.
Ezeket a meggyónt tételeket még nem mindig lehet egy az egyben elfogadni. Még akkor is, ha az Undetermined vagy az Unavailable szavakat tartalmazó rekordokat is beszámítjuk egy adott indexben, az összeg nem adja ki az adatbázisban meglevő rekordok teljes számát. Ez teljesen nyilvánvaló a Marquis Who's Who adatbázisban, ahol a nemek mezőjében négyféle érték van (9.14. ábra), de a hozzájuk tartozó rekordok mennyisége még mindig nem éri el a rekordok teljes számát. Ha csak azokat a rekordokat nézzük át, amelyekben a nem meghatározatlan, kíváncsiak lehetünk arra, miért olyan nehéz meghatározni olyan emberek nemét, akiknek a keresztneve Tatiana vagy Charles, és még az életrajzban is lehetnek további nyomravezető jelek.

9.14. ábra: Meghatározatlan nemre vonatkozó információk a Marquis Who's Who adatbázisban
A címjegyzék adatbázisokban a 9999 az általánosan használt kód annak jelzésére, hogy egy numerikus adatelem nem elérhető. Például, ha a Standard Industry Classification (SIC) kód nem határozható meg egy cég esetében, ezt a számot használják. A kód szöveges megfelelője nem állandó, változik. Egyes adatbázisokban ez nem osztályozott (nonclassified vagy unclassified) dolog, másokban osztályozhatatlan. Eltűnődhetünk, hogy ki által nem osztályozható. Ez a konvenció a fájlok készítőinek elég nagy mozgásteret ad, s úgy tűnik, ezzel vissza is élnek.
Az American Business Information (ABI) címjegyzékben több mint 100000 rekord van, ahol a SIC kód helyén 9999 szerepel. Felfoghatatlan, hogy olyan cégek, mint az Office Machines & Furniture és az Office Depot miért osztályozhatatlanok (9.16. ábra). Azt lehetne gondolni, hogy a SIC 502112 (OFFICE FURNITURE & EQUIP-DEALERS [WHOL], irodai bútor és berendezés-szállítók) vagy valamelyik variációja megfelelő lenne, ahogy 15000 cég valóban meg is kapta ebben az adatbázisban.
A Moody's Corporate News adatbázis a 9999-et adta a Walt Disney Companynak (9.17. ábra), pedig gyerekjátéknak látszik ennek meghatározása. A Dun & Bradstreet valószínűleg nem kápráztatja el az ügyfeleket azzal, hogy a 9999-et vágja hozzá olyan cégekhez, mint az America Online, American Eagle Airlines és a Burger King Corporation (9.18. ábra). Ennyi pénzért, amit fizetünk, azt lehetne várni, hogy a cég megengedheti magának, hogy olyan embereket alkalmazzon, akik képesek kitalálni, milyen SIC kódok illenének legjobban ezekre a cégekre.

9.15. ábra: Rengeteg olyan rekord van az ABI címjegyzékben, amely a 9999-es SIC kódot kapta.

9.16. ábra: Az Office Depot mint osztályozhatatlan szervezet az ABI címjegyzékben.

9.17. ábra: A Walt Disney Company a 9999-es kódot kapta a Moody'stól.

9.18. ábra: Az America Online, American Eagle Airlines
és Burger King a 9999-es kódot kapta a Dun & Bradstreettől.
A Bowker cég akkor használja a 9999-es értéket, amikor a megjelenés éve nem ismert. Ez elfogadható megoldás lenne, de sok adatbázisban vannak problémái. Az ilyen kódokat vagy figyelmeztetéseket nagyon gyakran nem következetesen használják, s ezzel félreinformálják a használót. Ha ismerjük egy adatbázisban a rekordok teljes számát, megpróbálhatunk egy teljesen csonkolt keresést, mint például PY=?, amely azt jelenti, hogy "Keress meg minden rekordot, amelynek bármilyen értéke van a megjelenés éve mezőben." Ha az ennek eredményeként kapott halmaz kisebb, mint a rekordok teljes száma, akkor tudjuk, hogy hány rekordnak nincs semmilyen értéke az adott mezőben - még figyelmeztető kódja vagy szövege sem. Ebben az esetben 66 rekordban található meg a speciális 9999-es kód a PY mezőben, de még ezekkel együtt is közel 80000 másiknak nincs semmilyen értéke a PY mezőben (9.19. ábra). Ez ellentétes azzal a céllal, ami miatt a 9999-es értéket használják a Books in Printben.

9.19. ábra: A 9999-es kód félrevezető használata a Books in Printben
Honnan tudhatjuk meg egy adatbázis teljes méretét? Elfogadhatjuk azt, amit a tartalomszolgáltató vagy az adatbázis kiadója mond (bár némi fenntartásokkal). Ennél jobb, ha keresést végzünk az UD (Update, aktualizálás) indexben - vagy teljesen csonkolt keresést használva, vagy aritmetikai művelettel, mert ezt a mezőt automatikusan generálják, amikor az adatbázist aktualizálják.
A 9.20. ábra az ERIC adatbázis DIALOG-os változatában mutat be egy ilyen keresést, amely kihagyások jelentős mennyiségét tárja fel. Jegyezzük meg, hogy az UD mező néha az adatbázis újra betöltésének dátumára vonatkozik. Ez azért van, mert sok címjegyzéket nem aktualizálnak, hanem újra betöltenek (azaz a rekordokat törlik és módosítják aszerint, ahogy a címjegyzék tárgya változik). Ez történik például akkor, amikor egy cégnek a székháza elköltözik vagy addigi vezetőjét egy újabb váltja fel. Ha az UD mező nem elérhető, van néhány más adatelem, amely nagy valószínűséggel minden rekordban megtalálható és kereshető (és csak néhány lehetséges értéke van). Ezek további keresési eredményekkel is igazolhatók lehetnek.
A 9.21. ábra megmutat egy teljességet igazoló keresést a Bowker's Complete Video Directoryban. Bár nincs benne UD mező, nagy biztonsággal kijelenhetjük, hogy 192166 rekord van az adatbázisban. A kulcsszavak indexében végzett teljesen csonkolt keresés (kw=$) a legjobb igazolása az adatbázis méretének, mert megszámol minden rekordot, amelyben bármilyen információ van bármelyik mezőből, függetlenül a mező tartalmától. Nagyon tanulságos megtudni, hogy a rekordok csaknem egyharmadában nincs adat a PC (publication code, kiadási kód) mezőben, 43%-ban nincs benne a gyártás éve, s a rekordok több mint 75%-ában nincs kibocsátási év, s körülbelül 8000 rekordban nincs információ, arról, hogy mi a videó témája.
Hasonló keresés elvégezhető az Ulrich's Plus adatbázisnak a Bowker által kiadott CD-ROM változatában. A teljesen csonkolt és a több indexben végzett numerikus keresések világosan megmutatták, hogy 226276 rekord volt az adatbázisban. A számok azt is megmutatták, hogy mennyire hiányos sok rekord (9.22. ábra).

9.20. ábra: A rekordok teljes számának keresése az ERIC DIALOG-os változatában.

9.21. ábra: A teljességre vonatkozó keresés a Bowker's Complete Video Directoryban.

9.22. ábra: A teljességre vonatkozó keresés az Ulrich's Bowker által kiadott CD-ROM változatában.
A teljességet megállapító keresések mindig adatbázis specifikusak, s feltételezik az adatbázisban alkalmazott hagyományok ismeretét. Egyes adatbázisokban a nyelvi mezőt csak a nem angol nyelvű dokumentumok esetében adják meg, feltételezve, hogy az angol az alapértelmezett érték. Ugyanez érvényes egyes adatbázisokban, ha a megjelenés országa az Amerikai Egyesült Államok. Hasonló módon az ERIC-ben a rekordok teljes száma könnyen meghatározható, bármilyen szoftvert használva, ha két keresést végzünk, és összehasonlítjuk ezek eredményeit másokéval.
Az ERIC-ben minden rekord vagy a RIE (Resources in Education), vagy a CIJE (Current Index to Journals in Education) részhalmazhoz tartozik. Néha a mezőspecifikus indexek átnézése azonnal jelzi, ha komoly problémák vannak egyes adatelemek nem teljes voltával. Az adatbázisok Ovidos változatának sok mezőspecifikus indexe jól illusztrálja ezt. Például a státusz kódok értékeinek átnézése az Ulrich'sban azonnal tájékoztat minket arról, hogy a rekordok teljes száma valahol 236000 közelében lehet ebben a fájlban (9.23. ábra).
Néhány mező jelenléte könnyen meghatározható úgy, ha rákattintunk a jelölőnégyzetekre vagy alkalmazzuk az előre meghatározott korlátokat, egy olyan keresés után, amely meghatározza a rekordok teljes számát. Az Ovidnál a rekordok teljes száma meghatározható a 19$.ud parancs alkalmazásával, amely visszakeres minden rekordot, amely 1900 és 1999 között került be az adatbázisba. Amikor a PAIS Ovidos változatában az összes kiadványtípusra és az összes nyelvre vonatkozó keresés is ugyanannyi rekordot eredményez, az azt bizonyítja, hogy minden rekordban van mind kiadványtípus, mind nyelvi mező (9.24. ábra).
Ha a WebSPIRS-ben minden olyan rekordra keresünk, amelynek az aktualizálási dátuma nagyobb nullánál, megkapjuk a rekordok teljes számát. Ezt követően ez a halmaz korlátozható az angol majd a nem angol nyelvű dokumentumokra, hogy lássuk, van-e valami különbség. A DIALOG-ban ezt a műveletet a SELECT parancs limit szuffixumával végezzük, hogy megtudjuk például azt, hogy csak minden második rekordban van a példányszámra vonatkozó információ (9.25. ábra).

9.23. ábra: Egy kevés értéket tartalmazó index átnézése az Ovidban.

9.24. ábra: A kiadványtípus és a nyelvi mező teljességének összehasonlítása a PAIS Ovidos változatában.

9.25. ábra: A példányszám mező teljességének meghatározása az Ulrich's DIALOG-os változatában.
A hatékony kereséshez alapvető annak ismerete, hogy egy adatbázisban a mezők hiányosak. Ennek az adatnak azonnal elérhetőnek kellene lennie nemcsak a reklámanyagokban, de feltűnő helyen a képernyőn is az adatbázis indításakor. Az ilyen adatok figyelmeztetnék a használót például arra, hogy a legnagyobb példányszámú folyóiratok megtalálása az Ulrich's adatbázisban reménytelen, mivel a rekordok felében nincs ilyen adat, vagyis kizárnánk őket az ilyen keresésből. Legalább ennek az adatbázisnak az esetében a használó megtanulhatja, hány rekordban nem található meg egy bizonyos adatelem.
A The Serials Directory esetében a használónak a semmi információja sincs erre vonatkozóan. A keresés korlátozására gyakran használt adatelemek nagymértékű hiánya drámai módon torzíthatja a keresési eredményeket. A hiányzó mezők hatásának tetőfoka az, amikor teljesen tönkreteszik a keresést - például akkor, amikor a megjelenési évet, a dokumentumtípust és a nyelvet használják a keresés korlátozására.
Még tovább rontja a dolgot, ha a reklámanyag írója nincs tisztában ezekkel a korlátokkal, s olyan keresést ajánl, amely nulla rekordot eredményez. A Bowker's Complete Video Directory (BVCD) 2000 tavaszi kiadása illusztrálja ezt az esetet, s összegzi annak következményeit, ha több olyan mező hiányos, amelyet a keresés finomítására használnak.
A rekordok sok keresési szempontból hiányos voltának bénító hatása van a legtöbb keresésre. A rekordok teljességét igazolni akaró tesztkeresések (9.26. ábra) lehangoló eredményeket hoznak a legújabb kiadásban is. Bár tárgyi deszkriptorokat a rekordok 95%-a kapott, a kiadás éve csak a rekordok 45%-ában van jelen, a videón való megjelentetés éve csak 28%-ban, a 21% a jelzi, hogy milyen nézőtípusnak szánják a filmet, a szín 63%-ban és a nyelv 6%-ban.

9.26. ábra: A teljesség tesztelése a Bowker's Complete Video Directory 2000 tavaszi kiadásában.
Ez a rendkívüli mértékű kihagyás nem gátolta meg a reklámszöveg íróját abban, hogy az adatbázis kereshetőségével próbálja eladni az adatbázist. Tényleg kereshetünk 19 keresési szempont szerint, de biztosan nem találjuk meg azt, amit szeretnénk, mivel az, hogy 19 keresési szempont közül sok hiányzik rekordok tízezreiből, drasztikusan leszűkíti a kereshető rekordok számát, amely tényről a használónak a legcsekélyebb fogalma sincs.
A reklámszöveg írója az éjféli információs tévéprogramok túláradó stílusában próbálja rávenni a használót arra, hogy állítson össze a videókról meghatározott feltételeknek megfelelő listát, például minden 1988-ban angol nyelven kiadott, PG minősítésű (csak szülő felügyelet mellett nézhető) vígjátékról. Kezdjük azzal, hogy a megjelentés éve csak a rekordok 28%-ában található meg, így a keresési tartomány egyből 47399 rekordra korlátozódik. Csak 3249 film felel meg az 1988-as megjelenés feltételének. A korhatár csak a rekordok 11%-ában található meg (nem is kell magas százalékot várni erre az adatelemre, mert sok filmnek nincs korhatár-jellemzője).
Ön 19 szempont szerint kereshet önmagában vagy kombinálva őket, vagy átnézheti a címjegyzék kilenc böngészhető indexét.
Megoldhatja akár a legnehezebb kérdéseket is, mint például "Tud olyan francia filmet találni, amelynek a címében szerepel a "blue" (kék) szó?
Megjelenítheti és kinyomtathatja több mint 5500 kritika teljes szövegét a Variety című folyóiratból, évente újabbak ezrei adódnak az adatbázishoz
Negyedévenkénti kumulatív aktualizálásokkal folyamatosan információt kaphat a legújabb videókról és kritikákról
Összeállíthatja videók olyan listáját, amely megfelel meghatározott szempontoknak, mint például "minden 1998-ban kiadott PG minősítésű angol nyelvű vígjáték"
A könyvtárak és a kiskereskedelmi boltok ügyfeleinek önkiszolgáló videó információs központot ajánl, a képzetlen személyzetet rövid idő alatt videók szakértőjévé teheti
Megkönnyíti a rendelést, a címek megtalálásával és a rendelőlapok kinyomtatásával egyetlen könnyű folyamattá egyszerűsíti a megrendelést
Negyedévenként aktualizált.
Windowsos és MS-DOS-os formában érhető el.
1 éves előfizetési díja 520 dollár.

9.27. ábra: A katalógus kihívása és hallgatólagos ígérete - és a valóság.
Ahogy az látható a keresés előrehaladásából (9.28. ábra), az első két kritérium szerinti kombináció a választékot 145 rekordra szűkítette. A vígjáték feltételének hozzáadása a keresést 44 filmre szűkíti (9.29. ábra). Az utolsó lépés teszi igazán vígjátékká a dolgot, amikor az angol nyelvre korlátozza a keresést, s nulla találatot kap (9.30. ábra). Az üzenet a Books in Print adatbázisra utal (ahogy a súgó nagy része), bár a videó címjegyzékben kerestünk, ahogy az a képernyő tetején látható.

9.28. ábra: A keresés első lépései.

9.29. ábra: A keresés szűkítése a vígjáték műfajára.

9.30. ábra: Nem kapunk találatokat, maga a keresés válik vígjátékká.
Az örömködő reklámszövegíró nem ellenőrizte a szánalmas súgó fájlt (s attól félek, hogy a használók sem tennék ezt), amely azt mondja, hogy "az ENG (English, angol) kifejezés csak a többnyelvű könyvekre használatos" (9.31. ábra). Ha a könyveket filmekkel helyettesítjük, akkor ez többnyelvű filmeket jelentene. Csak 540 ilyen rekord van, és egyik sem 1988-ban megjelentetett vígjáték. Ezért nem kapunk egy találatot sem.
A nyelvi kód szerint való keresés lehetővé teszi önnek, hogy visszakeresse az összes nem angol nyelvű könyvre vonatkozó leírásokat.
ENG (English, angol) csak többnyelvű könyvek esetében használatos
Példák
La=fre or ger
visszakeres minden francia vagy német nyelvű könyvet
su=medicine and la=fre
visszakeres minden francia nyelvű, az orvostudománnyal foglalkozó könyvet
su=medicine andnot la=fre and il=x
visszakeres minden olyan, az orvostudománnyal foglalkozó illusztrált könyvet, amely nem franciául jelent meg

9.31. ábra: A súgó könyvekre utal, de azért ad némi útmutatást.
Egy dolog az, hogy az adatbázist ilyen szörnyű állapotban tartják. Másik dolog a nonszensz reklámanyag, amelyet azonnal el kellene távolítani a webről. Nyilvánvaló, hogy a Bowkernek nem áll érdekében, hogy ezt megtegye, amíg elég könyvtár van, amely örömmel fizet 520 dollárt a BVCD-ért.
A sok információban gazdag, naprakész, pontos és ingyenes mozi adatbázis mellett a BVCD-nek nincs jövője. A könyvtárosok rá fognak jönni, hogy a Bowker jól ismert nevével egy szánalmas adatbázist ruházott fel.


